Spark: DataFrame Partitions and Executors
Dataframe Introduction
- Do not want to hardcode the data file name and location in my application -> 파일 이름은 commandline argument를 통해 전달
- DataframeReader is your gateway to read the data in Apache Spark.
Spark에서 InferSchema option은 DataFrameReader가 파일의 부분을 읽어서 데이터의 스키마를 파악하는 용도임.
아래 Spark Document에서 InferSchema에 대한 옵션을 확인할 수 있음.
아래는 간단하게 Sample data를 불러와서, 터미널에 출력해보는 코드이다.
sample_data의 출처는 아래 github에서 다운받아 사용하였다.
(sample_data 출처)
Spark-Programming-In-Python/03-HelloSparkSQL/data/sample.csv at master · LearningJournal/Spark-Programming-In-Python
Apache Spark 3 - Spark Programming in Python for Beginners - LearningJournal/Spark-Programming-In-Python
github.com
# HelloPyspark.py
import os
import sys
from pyspark.sql import *
from lib.logger import log4J
from lib.utils import get_spark_app_config, load_survey_df
from pyspark import SparkConf
log_dir = "logs"
print("HADOOP_HOME:", os.environ.get("HADOOP_HOME"))
if not os.path.exists(log_dir):
os.makedirs(log_dir) #log 폴더 없으면 생성
if __name__ == "__main__":
conf = get_spark_app_config()
# create pyspark session
spark = SparkSession.builder \\
.config(conf=conf) \\
.getOrCreate()
logger = log4J(spark)
if len(sys.argv) != 2:
logger.error("Usage: HelloSpark <filename>")
sys.exit(-1)
logger.info("Starting HelloSpark")
survey_df = load_survey_df(spark, sys.argv[1])
survey_df.show()
logger.info("Finished HelloSpark")
# spark.stop()
# create a new Class for handling log4J and expose simple and easy to use methods to create a log entry
# lib.utils
import configparser
from pyspark import SparkConf
def get_spark_app_config():
spark_conf = SparkConf()
config = configparser.ConfigParser()
config.read("spark.conf")
for(key, val) in config.items("SPARK_APP_CONFIGS"):
spark_conf.set(key, val)
return spark_conf
def load_survey_df(spark,data_file): # spark_session, file_location
return spark.read \\
.option("header", "true") \\
.option("inferSchema", "true") \\
.csv(data_file)
# logger.info("Finished HelloSpark")
# spark.stop()
DataFrame 출력 결과는 아래와 같다. 현재는 1개의 partition 내에서 연산이 수행되고있다.
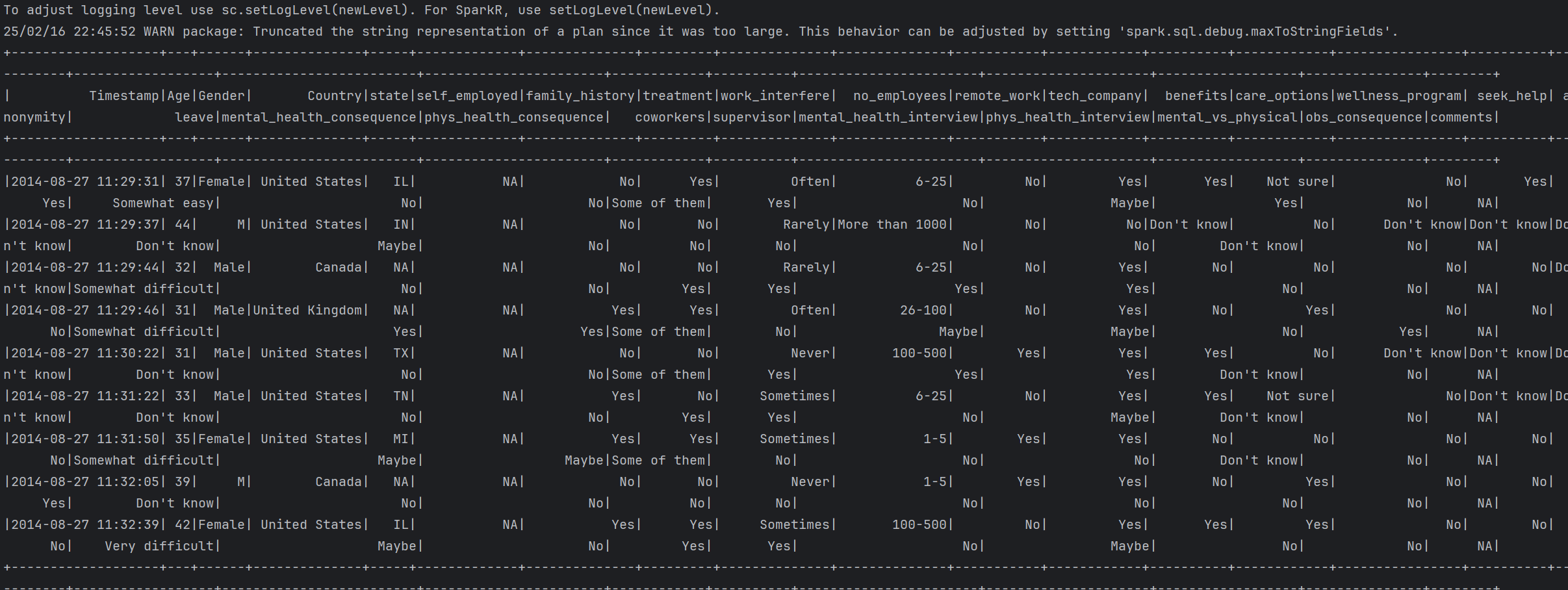
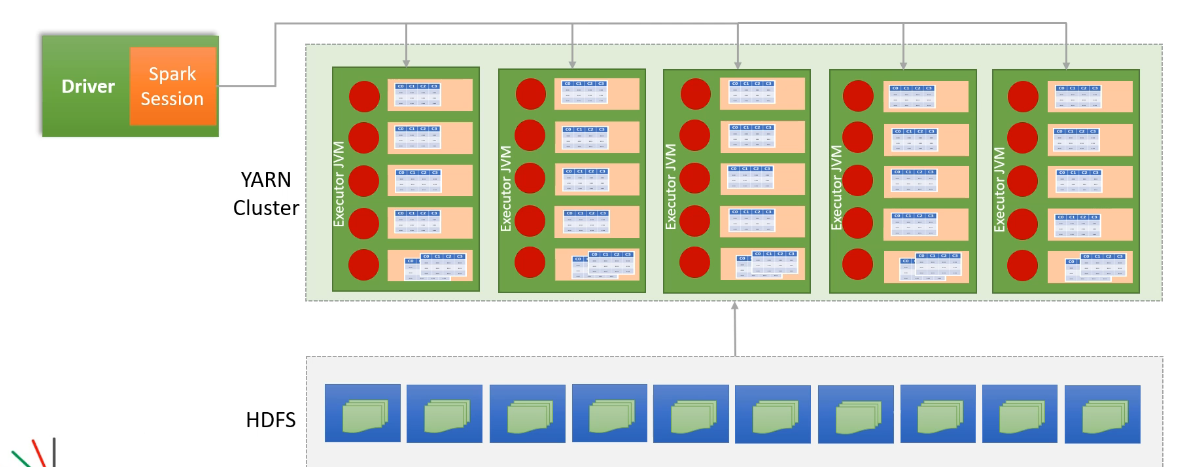
Apache Spark는 대규모 데이터를 분산 처리하기 위해 DataFrame과 RDD를 여러 개의 파티션(Partition)으로 나누고, Executor에서 병렬로 연산을 수행하는 구조를 갖는다.
Spark의 실행 과정에서 DataFrame Partition과 Executor가 어떻게 동작하는지를 살펴보고자 한다.
첫째로, SparkSession과 Driver의 역할이 무엇일까?
Spark 애플리케이션이 실행되면, SparkSession이 생성되며, 이는
Driver 프로세스에서 실행된다.
Driver는 애플리케이션의 메인 컨트롤러 역할을 하며, 아래의 역할을 수행한다.
- DataFrame을 생성하고 변환을 수행
- RDD(Resilient Distributed Dataset) 또는 DataFrame을 여러 개의 Partition으로 나눔
- YARN Cluster에 작업을 할당하고 실행을 모니터링
DataFrame의 Partitioning 과정
Spark는 기본적으로 데이터 크기와 클러스터의 리소스에 따라 자동으로 파티션을 나눈다.
파티션 개수는 Spark의 spark.sql.shuffle.partitions 설정값(기본 200) 및 입력 데이터에 따라 결정된다.
HDFS 또는 분산 저장소에서 데이터를 로드할 경우, 파일 블록 크기(HDFS 기본 128MB)에 따라 자동으로 파티션이 나뉜다.
각 파티션은 독립적으로 실행 가능하며, 서로 다른 Executor에서 병렬로 처리될 수 있다.
YARN Cluster에서 Executor 배치 및 실행
Driver는 YARN Cluster에 여러 개의 Executor를 요청한다.
YARN은 클러스터에서 사용 가능한 노드 리소스를 기반으로 Executor를 할당한다. 할당된 Executor는 JVM 프로세스 내에서 실행되고, 각 Executor는 여러 개의 CPU 코어와 메모리를 사용하여 병렬 작업을 수행한다.
+) 최적화 과정
Spark는 데이터가 저장된 위치(예: HDFS 블록 위치)를 기반으로, 가장 가까운 네트워크에 있는 Executor에 파티션을 할당하여 데이터 이동 비용을 최소화한다. 예를 들어, 특정 데이터 블록이 HDFS의 노드 A에 저장되어 있다면, 해당 블록을 처리할 Executor도 노드 A에 할당하는 방식으로 최적화된다. 이렇게 하면 네트워크 트래픽을 줄이고 성능을 향상시킬 수 있다.
- 가장 가까운 네트워크에 있는 exetutors에 할당될 수 있도록 최적화한다.
Executor의 역할 및 병렬 연산 수행
각 Executor는 JVM에서 실행되는 프로세스로서, 여러 개의 파티션을 병렬로 처리한다.
Executor는 CPU 코어 개수만큼의 Task를 병렬 실행한다.
각 Task는 DataFrame의 한 개의 파티션을 처리하며, 필요하면 캐싱(Caching) 또는 체크포인트(Checkpoint)를 사용하여 데이터를 저장할 수도 있다.
데이터가 연산되면, 필요에 따라 다른 Executor 또는 Driver로 데이터가 전송될 수도 있다.
최종 연산 결과 수집 및 정리
Spark의 Transformation(변환 연산)은 Lazy Execution(지연 실행) 방식으로 동작하므로,
- show(), collect(), count() 같은 Action 연산이 호출될 때까지 실행되지 않는다.
- Action이 실행되면, 각 Executor에서 처리한 데이터가 필요에 따라 Driver로 전송되거나 다시 HDFS/S3 같은 저장소로 저장된다.
이 과정에서 Shuffle 과정이 발생할 수 있으며, 성능 최적화를 위해 Broadcast Join, Partition 조정, Caching 등을 활용할 수 있다.
핵심을 요약하자면, Spark는 대용량 데이터를 여러 개의 파티션으로 나눈 후, 클러스터의 Executor에서 병렬로 처리하는 방식으로 동작한다.
- Driver는 SparkSession을 생성하고, 데이터를 여러 파티션으로 나눈다.
- YARN Cluster는 가장 가까운 네트워크의 Executor에 파티션을 최적화하여 배치한다.
- 각 Executor는 할당된 파티션을 병렬로 실행하여 연산을 수행한다.
위같은 동작을 통해 Spark는 대규모 데이터를 효율적으로 처리할 수 있으며, 리소스를 최대한으로 활용해 병렬 연산을 수행하는 것이 핵심 동작이다.
Spark Transformations and Actions
About Transformation
Transformation은 기존 DataFrame이나 RDD를 변경하지 않고, 새로운 DataFrame/RDD를 생성하는 연산이다.
DataFrame 원본을 수정하지 않고, 원하는 결과값을 뽑아내기 위해
data transformation을 수행하고 원본 데이터를 요구에 맞게 필터링, 매핑, 변형해서 새로운 데이터 구조를 만든다.
Narrow Dependency(좁은 의존성)과 Wide Dependency(넓은 의존성)
이때 하나의 파티션에서 독립적으로 수행되는 transformation이 있는 반면, 더 넓은 dependency를 가지는 transformation이 존재할 것이다.
- Narrow Dependency Transformation
좁은 dependency를 가지는 경우는 각 파티션에서 독립적으로 연산이 수행된다. 즉, 한 파티션의 데이터가 다른 파티션 데이터와 섞이지 않고 자체적으로 처리가 된다.
예를 들어, where절로 조건을 걸어 해당 조건을 만족하는 데이터를 뽑는 경우는 특정 조건을 만족하는 행만 선택하는 연산이므로, independently하게 하나의 partition에서 vaild한 results를 뽑아낼 수 있는 경우이다.
Narrow Dependency는 병렬 처리에 유리하고 성능이 좋다.
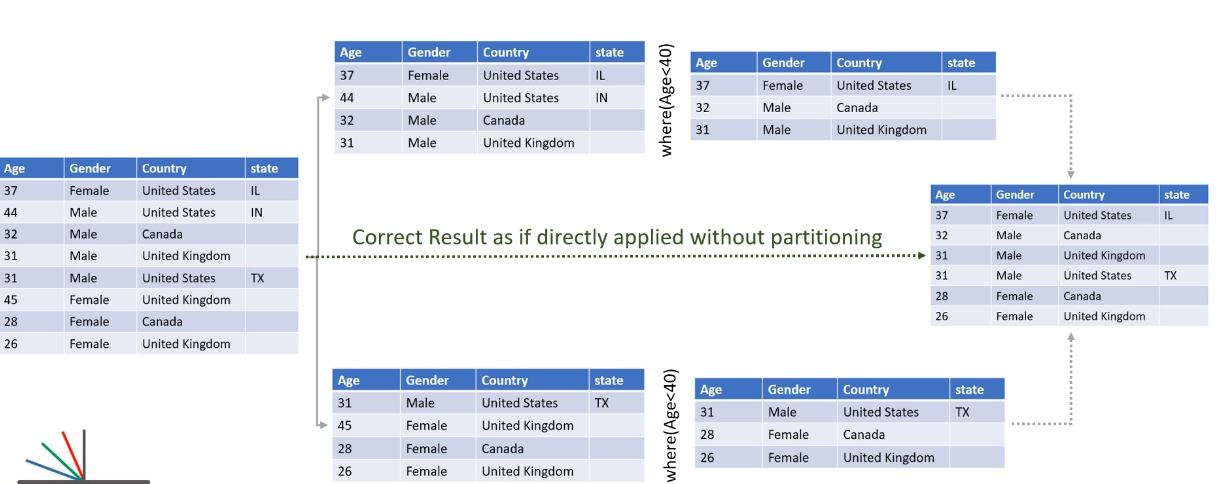
- Wide Dependency
Wide Dependency의 경우는 다른 파티션에서의 데이터를 이용해 results를 뽑아내는 경우를 말한다. 한 파티션의 데이터가 여러 다른 파티션의 데이터를 참조해야만 결과를 만들 수 있다.
네트워크 통신(suffle)이 필요하기 때문에 성능이 저하될 수 있다.
예를 들어 goupBy transformation을 예시로 들 수 있다.
같은 그룹들이 같은 파티션 안에 위치할 수 있도록 재정렬한다?
데이터를 Combining하고 Repartitioning하는 과정은 wide dependency transformation에 해당한다.
그 외에도 OrderBy(), Join, distinct 등등은 wide dependency한 transformation 연산이다. → shuffle/sort가 일어나는..
Wide Dependency는 네트워크 통신 비용(Shuffle)이 발생하므로 성능 저하 가능성이 크다!
- Lazy Evaluation
Spark의 Transformation은 즉시 실행되지 않는다.
아래처럼 line by line으로 작성되어있는 코드도 실제로 실행이 될 때는 individual operation으로 실행되지 않는다.
실제로는 계산을 미루고 있다가 Action이 호출될 때 optimized execution plan으로 전환된다.
아래 코드상으로는 show()(Action)이 실행되면 그제야 Spark가 모든 연산을 실행하기 때문에 Lazy Evaluation을 통해 최적화된 실행 계획을 수립할 수 있다.

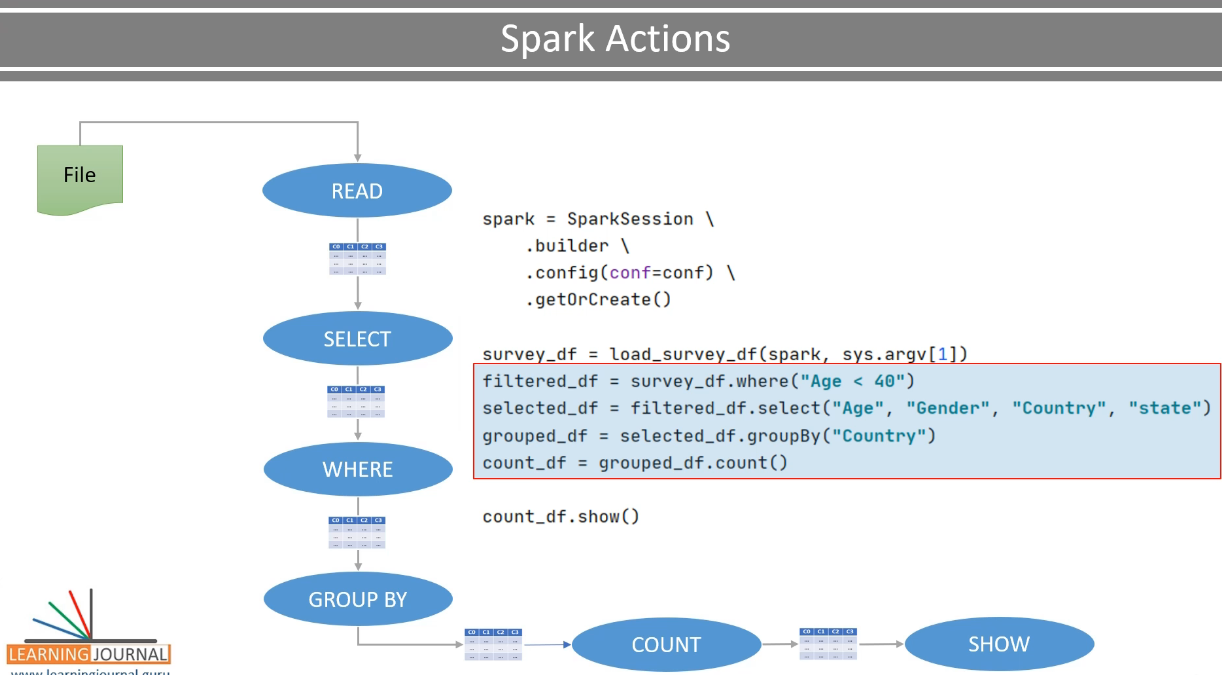
Spark Jobs Stages and Task
- Reading Dataframe & infering the schema
- survey_df = load_survey_df(spark, sys.argv[1])
- Applying a chain of transformation
- count_df = survey_df \\ .where("Age < 40") \\ .select("Age", "Gender", "Country", "state") \\ .groupBy("Country") \\ .count() count_df.show()
- execute Actions
- count_df.show()
위에서 수행했던 이런 일련의 작업들은 1개의 partition에서 일어나는 작업들이었다. 따라서 직접 Dataframe의 파티션을 분할하여 해당 코드가 어떻게 실행되는지 Spark UI에서 살펴보고자 한다.
따라서 코드는 아래와 같이 수정했다.
- 기존 단일 파티션 2개 파티션으로 나눔 → shuffle 발생 가능성 증가
- count_df.collect()를 실행해 전체 데이터를 Driver로 가져옴 → 추가적인 네트워크 비용 발생 가능
# HelloSpark.py
import os
import sys
from pyspark.sql import *
from lib.logger import log4J
from lib.utils import get_spark_app_config, load_survey_df, count_by_country
from pyspark import SparkConf
log_dir = "logs"
print("HADOOP_HOME:", os.environ.get("HADOOP_HOME"))
if not os.path.exists(log_dir):
os.makedirs(log_dir) #log 폴더 없으면 생성
if __name__ == "__main__":
conf = get_spark_app_config()
# create pyspark session
spark = SparkSession.builder \\
.config(conf=conf) \\
.getOrCreate()
logger = log4J(spark)
if len(sys.argv) != 2:
logger.error("Usage: HelloSpark <filename>")
sys.exit(-1)
logger.info("Starting HelloSpark")
survey_df = load_survey_df(spark, sys.argv[1])
partitioned_survey_df = survey_df.repartition(2)
count_df = count_by_country(partitioned_survey_df)
# filtered_survey_df = survey_df.where("Age < 40") \\
# .select("Age", "Gender", "Country", "state")
# grouped_df = filtered_survey_df.groupBy("Country")
# count_df = grouped_df.count()
logger.info(count_df.collect())
input("Press Enter")
logger.info("Finished HelloSpark")
# utils.py에 함수 생성
def count_by_country(survey_df):
return survey_df \\
.where("Age < 40") \\
.select("Age", "Gender", "Country", "state") \\
.groupBy("Country") \\
.count()
실행 결과를 UI에서 확인해 보니, Executor driver가 추가됨을 확인할 수 있었다. 이후 csv 파일 로드 → 데이터 재분배(repartition) → count_by_country() 실행 순서로 진행되었다.

- Job 0, 1이 csv 데이터를 로드하는 작업으로 보이고
- Job 2, 3, 4가 collect 연산과 관련되어있는데 repartition(2)를 적용했지만 일부 Task가 Skipped 된것을 보면 Spark가 이미 캐싱된 데이터를 활용하거나 최적화 과정에서 일부 작업을 생략했을가능성이 있다.
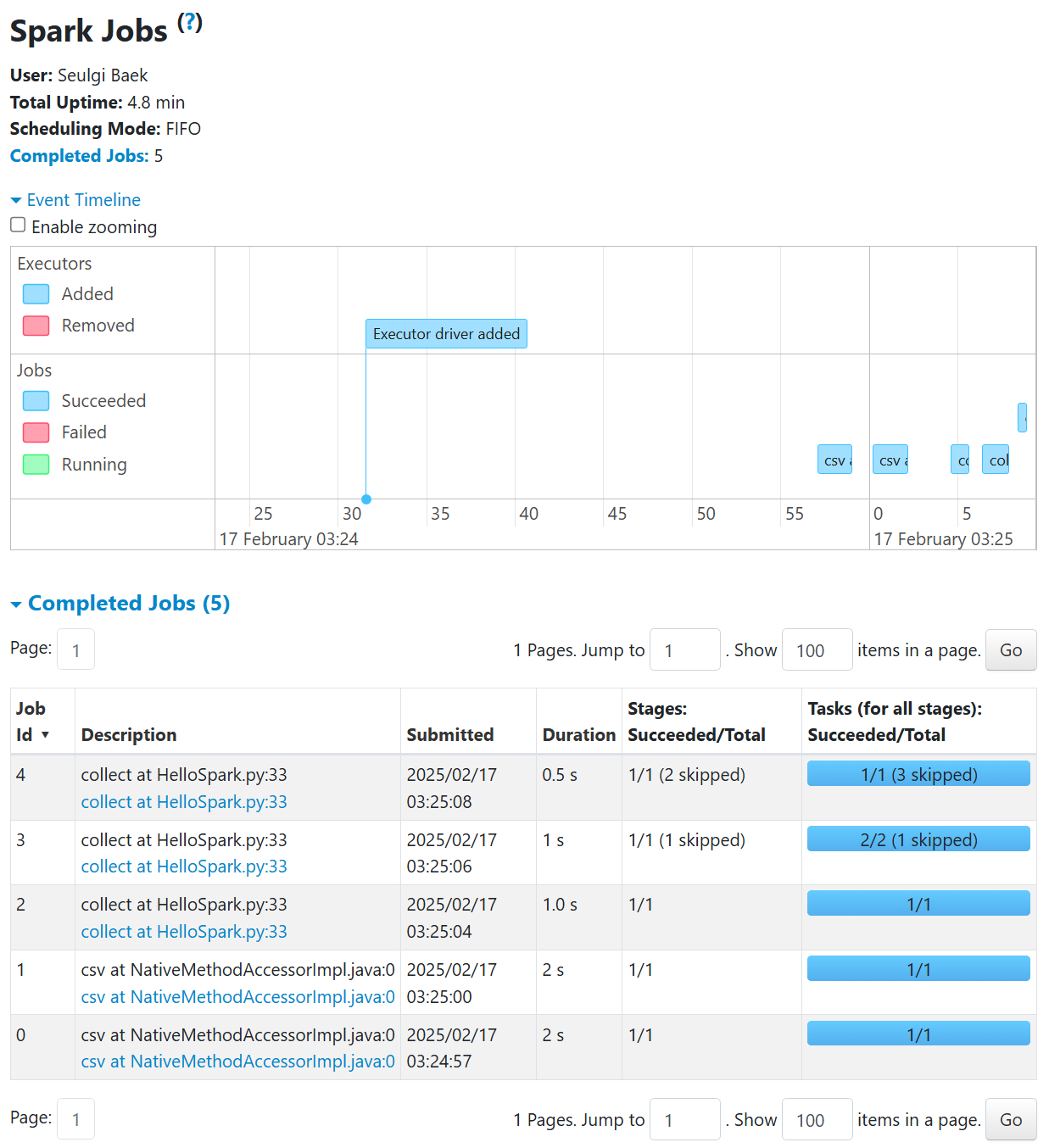
Spark Jobs, Stages, and Tasks
아래 이미지는 Spark의 Execution Plan을 시각적으로 나타낸 것이다.
Hello Spark 코드가 실행되면 여러 개의 Job이 생성되고 각 Job은 여러개의 Stage로 나뉘고, Stage 내부에서 Task가 실행된다.
이를 Spark UI에서 볼 수 있는 Jobs, Stages, Tasks 구조와 연결하여 설명하자면 다음과 같다.
Spark는 코드를 실행할 때 Job → Stage → Task의 계층 구조로 작업을 나눈다.
- 🔹 Job:
- Action(collect(), show(), count(), write())이 호출될 때마다 생성됨.
- 즉, df.collect(), df.show(), df.write() 등의 연산이 Job을 생성한다.
- 🔹 Stage:
- Job은 여러 개의 Stage로 나뉘며, Narrow Dependency 기준으로 분할됨.
- 즉, 같은 파티션에서 연산이 수행되면 같은 Stage에 포함되지만,Shuffle(데이터 이동)이 발생하면 새로운 Stage가 생성됨.
- 🔹 Task:
- Stage 내에서 개별적인 병렬 연산 단위.
- 예를 들어, 4개의 파티션이 있을 경우 각 파티션마다 하나의 Task가 실행됨.
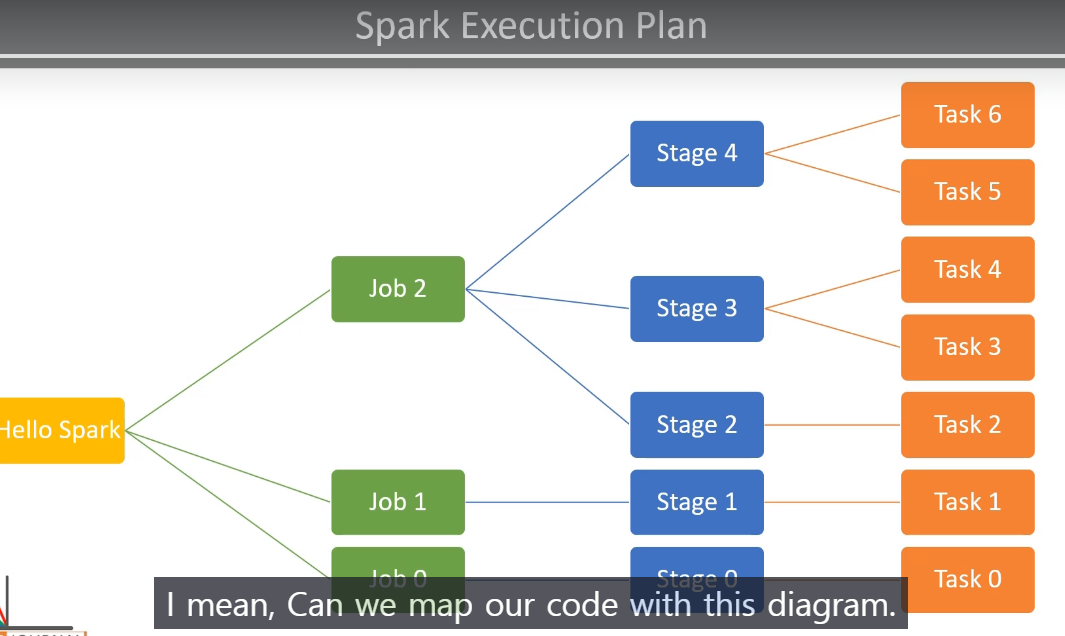
이 그림을 위에서 실행한 코드와 연결지어 살펴보자면, 아래와 같은 흐름을 ㅗ볼 수 있다.
1️⃣ Hello Spark.py 실행 후, Spark는 여러 개의 Job을 생성한다.
- Job 0: 데이터 로드 (spark.read.csv() 실행)
- Job 1: Transformation 연산 (repartition(2), where(), groupBy())
- Job 2: Action (collect() 실행)
2️⃣ 각 Job은 여러 개의 Stage로 나뉜다.
- Stage 0: CSV 파일 로드 (Job 0)
- Stage 1: where("Age < 40") 필터링 (Job 1)
- Stage 2: groupBy("Country") 수행 → Shuffle 발생
- Stage 3: 데이터 수집 (Job 2)
- Stage 4: collect() 실행하여 결과를 Driver로 가져옴
3️⃣ 각 Stage는 여러 개의 Task로 병렬 실행됨.
- Task 0 ~ Task 6: 각 Task는 개별적인 파티션을 처리
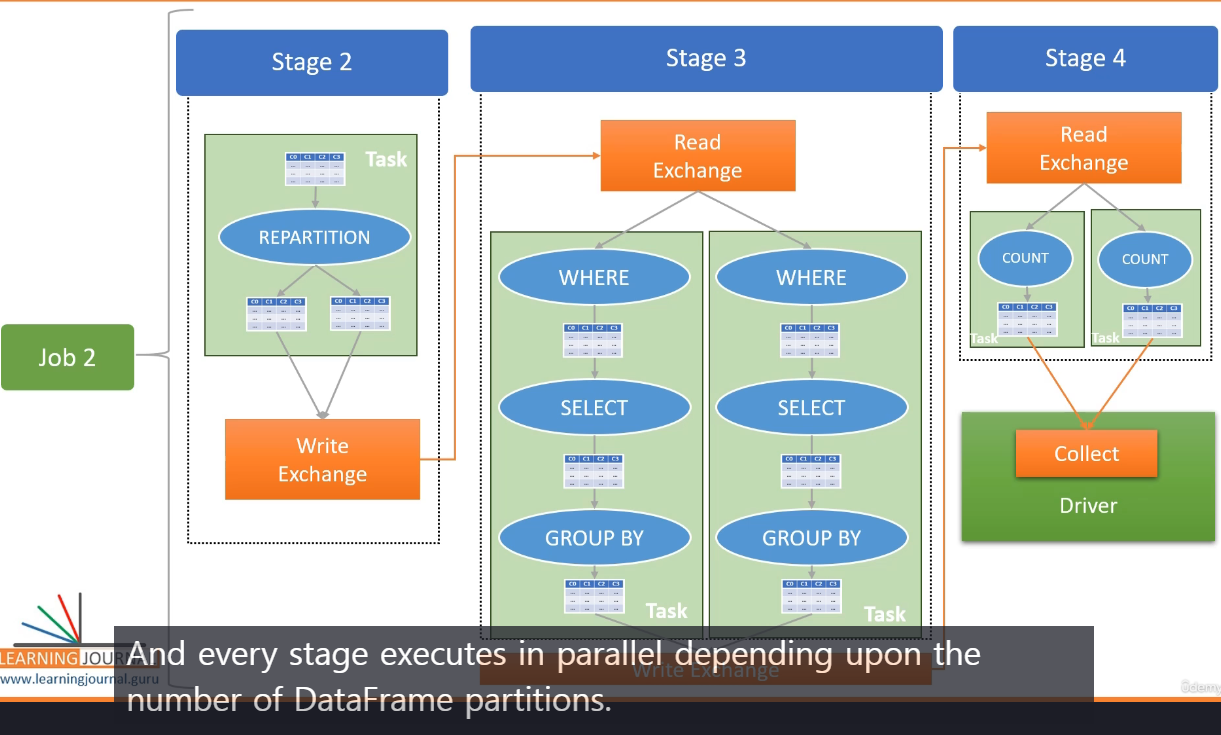
→ collection Action으로 트리거되는 동작들은 실제 여러작업을 수행하지만, Job은 1개로 구성된다.
