Multi Layer Perceptron
freedforward와 backward propagation의 계산

z_h = np.dot(X, self.w_h) + self.b_h
a_h = self._sigmoid(z_h)
z_o = np.dot(a_h, self.w_o) + self.b_o
a_o = self._softmax(z_o)
cost = np.sum(-y_enc*(np.log(output + 1e-7))/self.n_samples
z_h, a_h, z_o, a_o = self._forward(X)
delta_o = a_o - y
delta_h = np.dot(delta_o, self.w_o.T) * a_h * (1. - a_h)
grad_w_o = np.dot(a_h.T, delta_o) / self.batch_size
grad_b_o = np.sum(delta_o, axis = 0) / self.batch_size
grad_w_h = np.dot(X.T, delta_h) / self.batch_size
self.w_o = self.w_o - self.alpha * grad_w_o
self.b_o = self.b_o - self.alpha * grad_b_o
self.w_h = self.w_h - self.alpha * grad_w_h
self.b_h = self.b_h - self.alpha * grad_b_h
# softmax
def _softmax(self, z):
exps = np.exp(z)
return exps / np.sum(exps, axis=1, keepdims=True)
# prediction
def predict(self, X):
z_h, a_h, z_o, a_o = self._forward(X)
y_pred = np.argmax(a_o, axis = 1)
return y_pred
Stochastic Gradient Descent
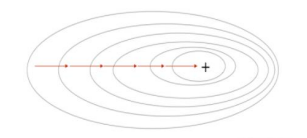
1) GD(Gradient Descent)
θ=θ−η∇θJ(θ)θ
손실 함수의 기울기(gradient)를 계산하여, 그 기울기가 가리키는 방향으로 반복적으로 매개변수를 조정함으로써 최소 손실 값을 찾는 방법이다.
한번 step을 내딛을 때, 데이터셋을 사용하여 손실함수의 기울기를 계산하므로 최적의 경로로 파라미터 값이 수렴하지만, 너무 많은 계산량을 필요로 한다.
2) SGD(Stochastic Gradient Discent)
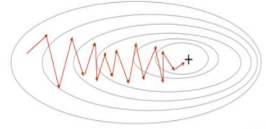
확률적 경사 하강법은 전체 데이터셋 대신 매 반복마다 무작위로 선택된 하나의 데이터 포인트를 사용해 손실함수의 기울기를 계산한다. 기울기의 근사치를 사용하므로 노이즈가 많이 발생할 수 있으나, 계산속도가 매우 빠르다.
3) Mini - batch SGD
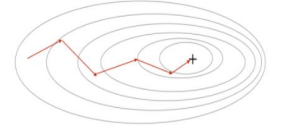
이 방법에서는 손실함수를 계산할 때, 전체 데이터 대신 일부 데이터의 모음(mini - batch)를 사용해 손실함수를 계산한다.
GD 보다는 다소 부정확할 수 있지만, 계산 속도가 훨씬 빠르기 때문에 같은 시간대에 더 많은 step을 갈 수 있고 여러번 반복할 경우 batch처리한 결과로 수렴한다. -> 노이즈 적고, 계산 효율적
Vanishing Gradients Problem
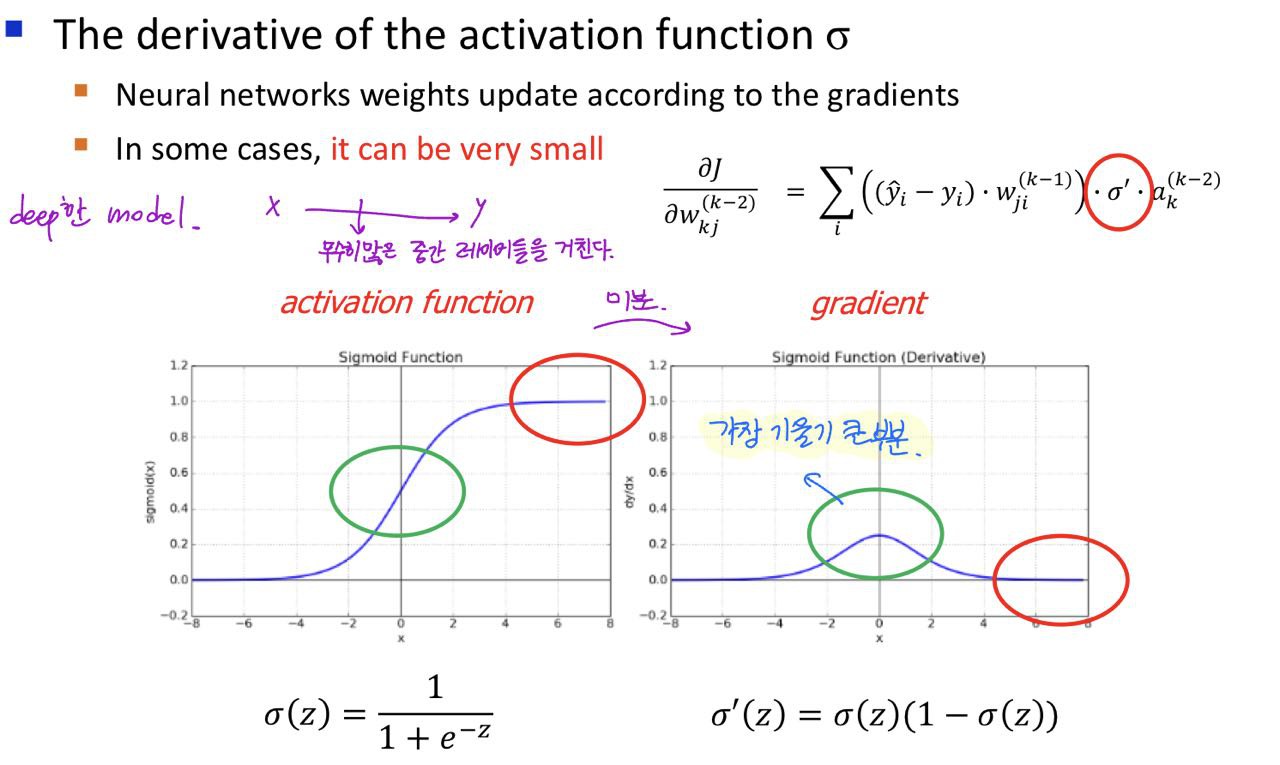
신경망에서 가중치는 역전파 알고리즘을 통해 업데이터되는데, 이때 그래디언트(기울기)를 계산하여 사용한다.
소실 그래디언트 문제는 신경망의 깊은 층으로 갈 수 록 그래디언트가 점점 작아져서 결국 거의 0에 가까워지는 현상을 말한다. 이로 인해 가중치가 제대로 업데이트 되지 않아 학습이 제대로 진행되지 않는 문제가 발생한다.
문제 발생 원인
- 그림과 같이 sigmoid activation function의 도함수는 최댓값이 0.25이다. 이 도함수는 입력값이 커지거나 작아질수록 빠르게 0에 가까워진다. 따라서 역전파시 이런 작은 도함수 값들이 곱해지면서, 그 결과로 생성되는 gradient가 점점 작아진다.
- 역전파는 chain rule을 사용해 각 층의 가중치에 대한 손실 함수의 그래디언트를 계산한다. 매 층마다 작은 그래디언트가 곱해지면서, 입력층에 가까운 층의 그래디언트는 매우 작아지게 된다.
즉, 결론적으로 그래디언트 소실 문제로 인해 네트워크 초기 층이 제대로 학습되지 않아 전체 학습 속도가 느려지고 신경망의 성능이 저하된다.
해결 방안
ReLU activation function을 사용한다.
- ReLU 활성화 함수는 양수 입력에 대해 gradient가 1이 되어 소실 그래디언트 문제를 완화할 수 있다.
- ReLU함수는 비선형 함수이기 때문에 신경망이 복잡한 함수를 학습할 수 있게 도와준다.
- Relu는 sigmoid나 tanh 함수보다 일반적으로 학습 속도가 빠르다.
- ReLU는 계산하기 매우 간단하므로(0 or 1) 연산 비용이 낮다.