https://youtu.be/ZBu_slSH5Sk?si=vhV5s68tyWXiLUhO
hash table: 배열과 해시 함수를 사용해 map을 구현한 자료구조
*상수시간으로 데이터에 접근
hash function: 임의의 크기를 가지는 type의 데이터를 고정된 크기를 가지는 type의 데이터로 변환하는 함수
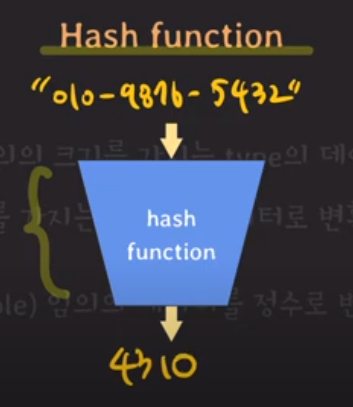
output=4310, 즉 이것이 hash임.
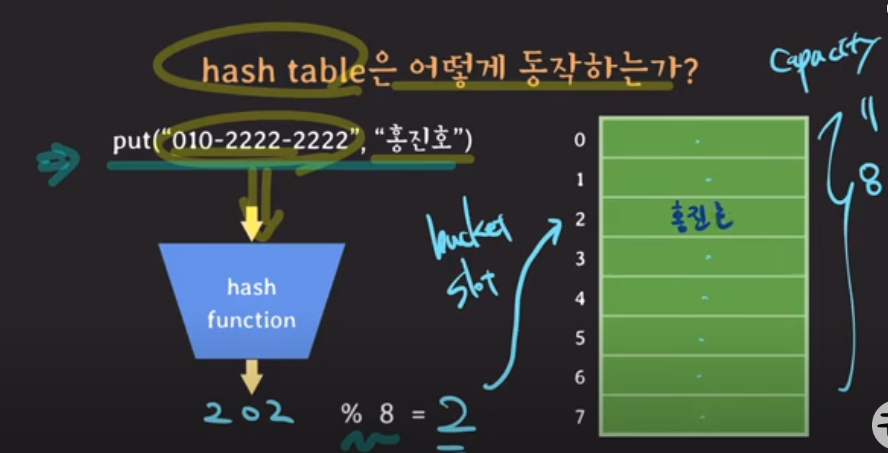
hash table의 capacity=8이라고 하면, (hashFunction을 거쳐 나온 값)%8 = 202 % 8 = 2
즉, hash값인 index=2에 홍진호라는 정보를 저장하는 것이다.
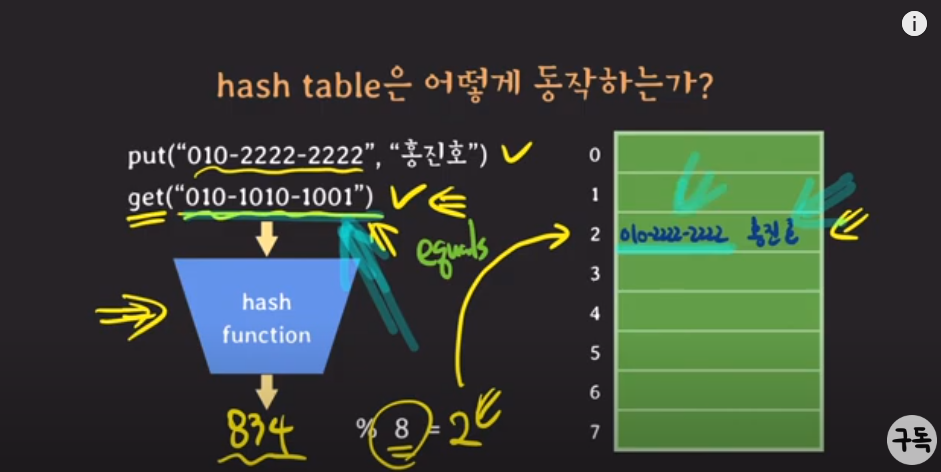
근데, key값이 다른데 hash값이 같아서 같은 인덱스로 값을 찾으러갔다?
이런 경우때문에 key(전화번호)도 함께 해시테이블에 저장해야 하는 것이다.
hash collision(해시 충돌): key는 다른데 hash가같을 때 발생/key도 hash도 다른데 hash % map_capa 결과가 같을 때
->hash 충돌은 언젠가 발생할 수 밖에 없다.(필연적이다.)
hash collision 해결 방법
1) seperate chaining 방식
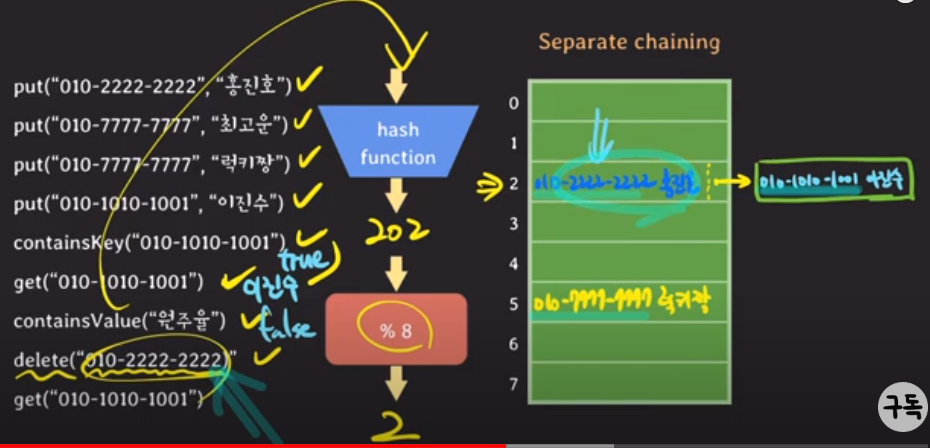
-"010-2222-2222" hash 값 = 2, index 2자리에 key("010-2222-2222"): value("홍진호") 저장
-"010-7777-7777" hash 값 = 5, index 5자리에 key: value 저장
-"010-7777-7777" hash 값 = 5, index 5자리에 이미 data가 있네? -> 내가 put한 key값과 배열의 key값이 같으면, value를 "럭키짱"으로 교체, key값이 다르면 linked-list로 data 추가
-"010-1010-1001" hash 값 = 2, index 2자리에 이미 data가 있네? -> 근데 key값이 서로 다르므로, put한 data를 linked-list 형식으로 추가("이진수" 추가됨)
-"010-1010-1001"이라는 key가 있는지 확인하고 싶음. -> hash = 2, index 2로 가서 key값 같은지 비교 -> 같으니까 return true
-"010-1010-1001"에 대한 value값을 얻고싶음. -> hash=2, index 2로 가서 key값 비교 -> 이진수 key값과 같으니까 return "이진수"
-"원주율"이라는 value를 가졌는지 확인하고 싶음. -> value는 애초에hash function으로 값을 얻는게 아니니까 배열에 존재하는 data 일일이 살펴봐야 함.
-"010-2222-2222"에 대한 data를 삭제하고 싶음. -> hash=2, index 2로 가서 같은 key값 있으면 그거 삭제
-"010-1010-1001"에 대한 value값 얻고싶음. -> hash=2 위치로 가서 key값 같은 것 찾아서 해당 value를 return
2) open addressing (linear proving) 방식
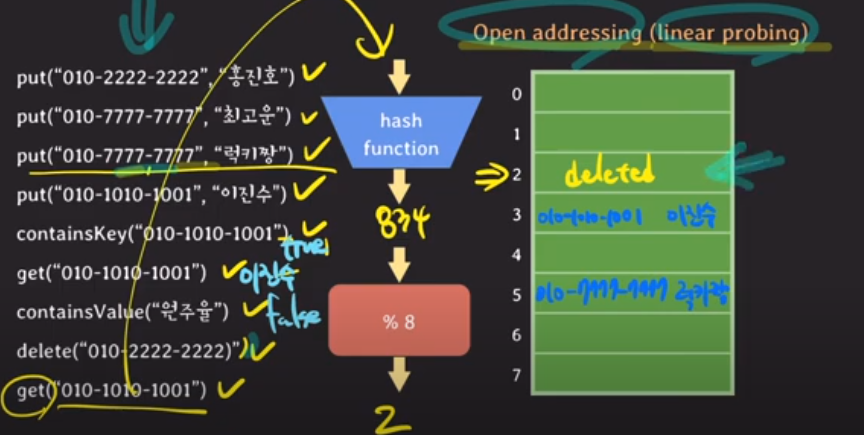
-key값은 다른데 hash값이 같아서 이미 해당 index에 데이터가 차있을 경우, linked-list방식으로 연결하는게 아니라, 바로 다음 index에 data를 저장.
-따라서 어떤 key값에 해당하는 value를 찾을 때, 해당 hash값에 해당하는 index에 원하는 data가 없을 경우 탐색을 그대로 끝내지 않고 원하는 key값이 나올 때까지 다음 버킷도 검사함.
-만약 어떤 key를 delete했는데, 어떤 data가 삭제된 자리에 있던 data때문에 다음 인덱스에 저장이 되었다고 하자. 그 사실을 모르는 탐색자는 해당 index가 비어있으니 이대로 탐색을 끝내야 할까? 해당 인덱스에 아직 아무 값이 들어가지 않았는지, 아니면 delete가 된건지 알기 위해서 delete하게 되면 그 안에 dummy값을 넣어줌으로써 인접 배열의 key값까지 확인해 볼 수 있도록 장치를 마련해야 한다.
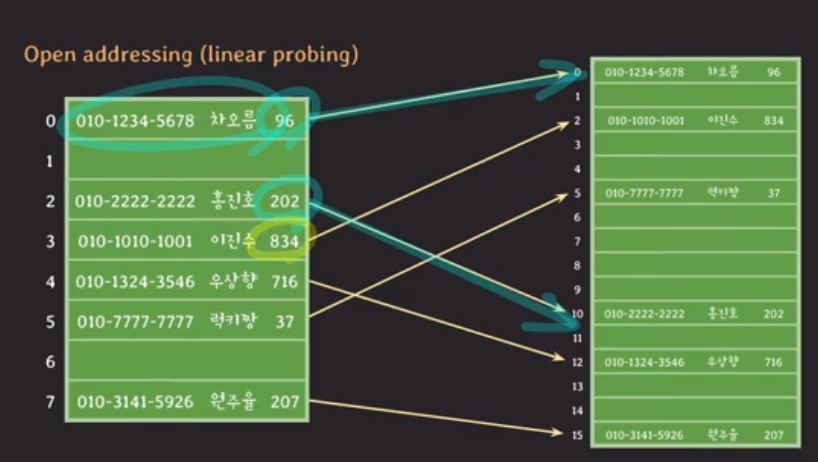
hash table resizing
data가 많이 차게 되면 hash table의 크기를 늘려줘야한다.
java hashmap같은 경우, 전체 capacity의 75% 이상이 차면 hash table의 size를 2배 늘려줌.
그럼 capacity도 2배로 늘어남.
hash값을 새 capacity로 moduler 연산을 해서 새로 배열에 배치.
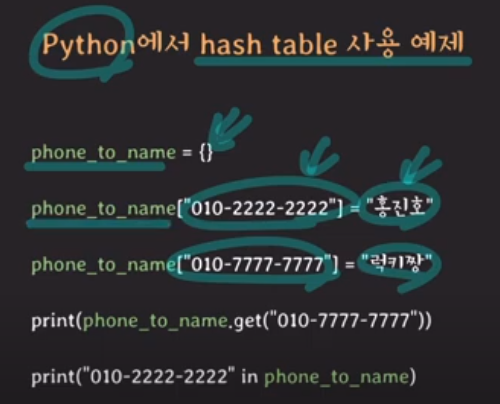
*Python에서 hash table 사용 예제