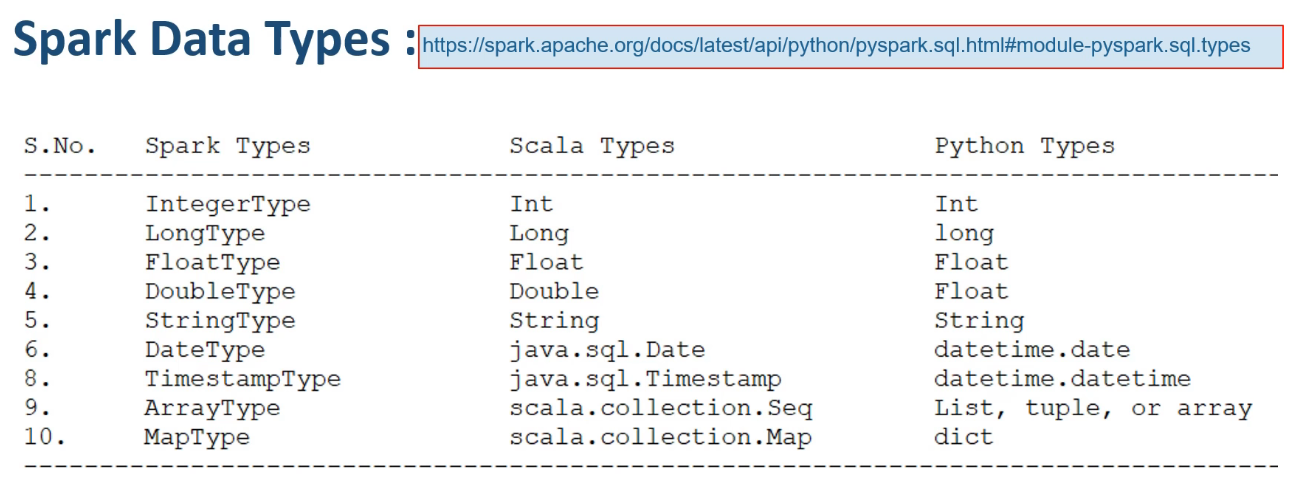
External Data sources
데이터들은 oracle이나 SQL Server같은 몇몇 source systems에 저장이 될 것이다.
some application servers에도 저장이 될 것이다.(application logs같은…) 하지만, 이 모든 시스템들은 내가 사용할 DataLake의 외부에 존재한다. 우리는 DataLake conceptual diagram에서 이들을 볼 수 없다.
- JDBC Data Sources
- Oracle, SQL Server, PostgreSQL
- NoSQL Data Systems
- Cassandra, MongoDB
- Cloud Data Warehouses
- Snowflake, Redshift
- Stream Integrators
- Kafka, Kinesis
위와 같은 External Data sources를 가져오기 위한 접근방식으로는 크게 두가지가 있다.
첫번째 접근은,
내가 사용할 데이터를 DataLake로 가져오는 것이다. 그리고 그 데이터들을 나의 DataLake’s distributed storage에 저장하는 것이다.
가장 흔하게 사용되는 방법은 sutiable data integration tool을 사용하는 것이다.
두번째 접근은,
Spark Data Source API를 이 external systems와 직접적으로 연결하는 것이다. Spark는 여러 source system과 이를 가능하게 해준다.

위 사진과 같이, 1) 사용할 데이터를 DataLake로 가져오거나 2) Spark DataSrouce API를 external system과 직접적으로 연결하는 방법이 있는데 각 방식은 어떤 상황에 적합할지 생각해보자.
첫번째 방법은 batch processing requirements에 적합하고,
두번째 방법은 stream processing requirements에 적합하다.
현재는 stream processing에 대해서는 다루지 않고, batch processing에 대해 공부해보자.
(Using a data integration tool to bring data to the distirbuted stroage and then start processing it.)
Internal Data sources
Internal Data sources는 DataLake내의 내부 분산 스토리지를 의미한다. 이는 HDFS나 클라우드 기반 스토리지(AWS S3, Azure Blob Storage 등)와 같이 데이터를 저장하는 분산된 파일 시스템이다.
결국, 내부 데이터 소스의 본질은 데이터 파일이다. Spark는 이런 파일에서 데이터를 읽고 처리하며 HDFS와 클라우드 스토리지에서 데이터를 읽는 방식은 동일하고, 파일 형식에는 여러가지가 있다.
데이터 파일 형식
- CSV: 가장 기본적인 text기반 형식. 쉼표로 구분된 데이터 저장
- JSON: 계층적 구조를 가짐. 데이터간 관계 표현에 적합
- Parquet: 컬럼 형식의 스토리지로 빠른 읽기와 압축 성능이 뛰어남.
- ORC: Parquet과 유사한 컬럼 기반 형식으로 Hadoop 생태계에서 주로 사용됨.
- Avro: 바이너리 형식. 데이터 직렬화와 빠른 처리 가능.
Spark SQL Tables와 Delta Lake
파일 형식 외에도 Spark SQL Tables와 Delta Lake도 내부 데이터소스에 포함된다. 단순한 데이터 파일이 아니고, 메타데이터와 트랜잭션 로그를 추가로 관리하는 특징이 있다.
- Spark SQL Tables: Spark 내에서 테이블 형태로 데이터를 관리할 수 있으며, Hive 메타스토어를 통해 테이블 정의를 저장.
- Delta Lake: ACID 트랜잭션과 스키마 진화를 지원하는 확장된 데이터 형식으로, 데이터 무결성을 유지하며 실시간으로 데이터를 관리할 수 있음.
Data Sinks(데이터싱크)
Data Sink는 Spark에서 처리된 데이터를 최종적으로 저장하는 위치를 의미한다. 데이터가 분석과 처리를 거친 뒤, 내부 스토리지 또는 외부 시스템에 저장되는 대상이다.
이 싱크 유형에도 Internal Data Sink와 External Data Sink로 나뉜다.
HDFS나 S3와 같은 분산 스토리지, 그리고 Spark SQL Tables 및 Delta Lake는 모두 Internal Data Sinks라고 생각하면 된다.
External Data Sinks로는 관계형 DB(JDBC: Oracle, MySQL, PostgreSQL emd), NoSQL(MongoDB, 카산드라 등), 클라우드 데이터 웨어하우스(Snowflake, Redshift) 등이 있다.
보통 Batch Processing을 하는 경우는 데이터를 먼저 DataLake로 가져온 뒤, 내부 분산 스토리지에서 처리하고 결과를 다시 내부 스토리지에 저장하는 방법이 권장된다.
Stream Processing을 하는 경우는 실시간 데이터 처리 시 Spark Streaming을 활용해 외부 시스템과 직접 연결하는 방법이 적합하다.
보안적인 측면에서는 내부 스토리지 중심 접근 방법을 사용하는게 안정적이다.
Spark DataFrameReader API
Apache Spark는 DataFrameReader API를 통해 다양한 데이터 소스에서 데이터를 읽을 수 있도록 표준화된 인터페이스를 제공한다. API는 데이터 형식, 옵션, 읽기 모드, 스키마를 설정한 후 데이터를 DataFrame 형태로 불러오는 역할을 수행한다. 전에 csv 파일을 DataFrameReader를 사용해 가져오는 것을 해보았을 것이다.
1. DataFrameReader 접근
df = spark.read.format("csv") \\
.option("header", "true") \\
.load("path/to/data.csv")
2. 지원하는 데이터 형식 (Format)
# JSON 형식 데이터 읽기
df = spark.read.format("json").load("dataSource/data.json")
DataFrameReader는 여러 데이터 형식을 지원하며, Spark 기본 형식과 커뮤니티 확장 형식으로 나뉜다.
- 기본 형식: CSV, JSON, Parquet, ORC, JDBC
- 외부 형식: Cassandra, MongoDB, XML, HBase, Redshift 등
3. 옵션 설정
df = spark.read.format("csv") \\
.option("header", "true") \\
.option("delimiter", ",") \\
.option("inferSchema", "true") \\
.load("dataSource/data.csv")
- header: 첫 번째 줄을 컬럼 이름으로 사용할지 여부
- delimiter: 데이터 구분자 설정
- inferSchema: 스키마를 자동으로 추론할지 여부
4. 읽기 모드 설정
데이터를 읽을 때, 손상된 레코드를 어떻게 처리할지를 결정한다.
- Permissive (default): 오류가 발생하면 해당 필드를 null로 처리하고, _corrupt_record 열에 손상된 데이터를 저장
- DropMalformed: 손상된 레코드를 무시하고 정상 데이터만 불러옴.
- FailFast: 손상된 데이터를 만나면 즉시 예외를 발생시키고 작업을 종료함.
5. 스키마(Schema)
inferSchema 옵션을 true로 설정하면, Spark가 자동적으로 스키마를 추론한다. 아래처럼 StructType과 StructField를 사용해서 스키마를 명확히 정의할 수도 있다.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([
StructField("Name", StringType(), True),
StructField("Age", IntegerType(), True),
StructField("Country", StringType(), True)
])
df = spark.read.format("csv") \\
.schema(schema) \\
.option("header", "true") \\
.load("path/to/data.csv")
Reading CSV, JSON and Parquet files
Apache Spark의 DataFrameReader API는 다양한 데이터 소스를 읽을 때 사용되며, CSV, JSON, Parquet 파일을 한번 읽어와보려고 한다. CSV 파일을 읽을 때 header 옵션을 true로 설정하면 첫 번째 행을 컬럼명으로 인식하지만, 스키마를 지정하지 않으면 모든 필드가 문자열로 처리된다.
inferSchema 옵션을 사용하면 숫자 필드는 자동으로 적절한 데이터 타입으로 변환되지만, 날짜 필드는 여전히 문자열로 처리되는 한계가 있다. JSON 파일을 읽을 때는 별도의 header 옵션이 필요 없으며, 스키마는 자동으로 추론되지만 정확성이 떨어질 수 있다.
반면, Parquet 파일은 데이터와 함께 스키마 정보를 포함하고 있어, DataFrameReader가 정확한 스키마를 적용하여 데이터를 불러올 수 있다. 따라서, Spark에서 데이터 처리 시에는 가능한 한 Parquet 파일 형식을 사용하는 것이 권장되며, 이는 성능과 정확성 모두를 보장하는 최적의 방식이다.
해당 결과는 아래 코드를 실행했을 때의 콘솔 출력 결과로 확인해볼 수 있다.
# 1. How to use DataFrame for CSV, JSON, and Parquet
# 1. Spark Data Types
# 2. How to explicitly define a schema for your data
from pyspark.sql import SparkSession
from lib.logger import Log4j
if __name__ == "__main__":
spark = SparkSession \\
.builder \\
.master("local[3]") \\
.appName("SparkSchemaDemo") \\
.getOrCreate()
logger = Log4j(spark)
flightTimeCsvDF = spark.read \\
.format("csv") \\
.option('header', "true") \\
.option("inferSchema", "true") \\
.load("data/flight*.csv")
flightTimeCsvDF.show(5)
print("CSV Schema: "+ flightTimeCsvDF.schema.simpleString())
# json & parquet 파일을 읽어올때는 항상 schema를 자동적으로 추론하기 때문에, inferSchema 옵션을 사용할 필요가 X.
flightTimeJsonDF = spark.read \\
.format("json") \\
.load("data/flight*.json")
flightTimeJsonDF.show(5)
print("JSON Schema: " + flightTimeJsonDF.schema.simpleString())
flightTimeParquetDF = spark.read \\
.format("parquet") \\
.load("data/flight*.parquet")
flightTimeParquetDF.show(5)
print("PARQUET Schema: " + flightTimeParquetDF.schema.simpleString())
+--------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
| FL_DATE|OP_CARRIER|OP_CARRIER_FL_NUM|ORIGIN|ORIGIN_CITY_NAME|DEST|DEST_CITY_NAME|CRS_DEP_TIME|DEP_TIME|WHEELS_ON|TAXI_IN|CRS_ARR_TIME|ARR_TIME|CANCELLED|DISTANCE|
+--------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
|1/1/2000| DL| 1451| BOS| Boston, MA| ATL| Atlanta, GA| 1115| 1113| 1343| 5| 1400| 1348| 0| 946|
|1/1/2000| DL| 1479| BOS| Boston, MA| ATL| Atlanta, GA| 1315| 1311| 1536| 7| 1559| 1543| 0| 946|
|1/1/2000| DL| 1857| BOS| Boston, MA| ATL| Atlanta, GA| 1415| 1414| 1642| 9| 1721| 1651| 0| 946|
|1/1/2000| DL| 1997| BOS| Boston, MA| ATL| Atlanta, GA| 1715| 1720| 1955| 10| 2013| 2005| 0| 946|
|1/1/2000| DL| 2065| BOS| Boston, MA| ATL| Atlanta, GA| 2015| 2010| 2230| 10| 2300| 2240| 0| 946|
+--------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
only showing top 5 rows
CSV Schema: struct<FL_DATE:**string**,OP_CARRIER:string,OP_CARRIER_FL_NUM:int,ORIGIN:string,ORIGIN_CITY_NAME:string,DEST:string,DEST_CITY_NAME:string,CRS_DEP_TIME:int,DEP_TIME:int,WHEELS_ON:int,TAXI_IN:int,CRS_ARR_TIME:int,ARR_TIME:int,CANCELLED:int,DISTANCE:int>
+--------+---------+------------+------------+--------+----+--------------+--------+--------+----------+-----------------+------+----------------+-------+---------+
|ARR_TIME|CANCELLED|CRS_ARR_TIME|CRS_DEP_TIME|DEP_TIME|DEST|DEST_CITY_NAME|DISTANCE| FL_DATE|OP_CARRIER|OP_CARRIER_FL_NUM|ORIGIN|ORIGIN_CITY_NAME|TAXI_IN|WHEELS_ON|
+--------+---------+------------+------------+--------+----+--------------+--------+--------+----------+-----------------+------+----------------+-------+---------+
| 1348| 0| 1400| 1115| 1113| ATL| Atlanta, GA| 946|1/1/2000| DL| 1451| BOS| Boston, MA| 5| 1343|
| 1543| 0| 1559| 1315| 1311| ATL| Atlanta, GA| 946|1/1/2000| DL| 1479| BOS| Boston, MA| 7| 1536|
| 1651| 0| 1721| 1415| 1414| ATL| Atlanta, GA| 946|1/1/2000| DL| 1857| BOS| Boston, MA| 9| 1642|
| 2005| 0| 2013| 1715| 1720| ATL| Atlanta, GA| 946|1/1/2000| DL| 1997| BOS| Boston, MA| 10| 1955|
| 2240| 0| 2300| 2015| 2010| ATL| Atlanta, GA| 946|1/1/2000| DL| 2065| BOS| Boston, MA| 10| 2230|
+--------+---------+------------+------------+--------+----+--------------+--------+--------+----------+-----------------+------+----------------+-------+---------+
only showing top 5 rows
JSON Schema: struct<ARR_TIME:bigint,CANCELLED:bigint,CRS_ARR_TIME:bigint,CRS_DEP_TIME:bigint,DEP_TIME:bigint,DEST:string,DEST_CITY_NAME:string,DISTANCE:bigint,FL_DATE:**string**,OP_CARRIER:string,OP_CARRIER_FL_NUM:bigint,ORIGIN:string,ORIGIN_CITY_NAME:string,TAXI_IN:bigint,WHEELS_ON:bigint>
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
| FL_DATE|OP_CARRIER|OP_CARRIER_FL_NUM|ORIGIN|ORIGIN_CITY_NAME|DEST|DEST_CITY_NAME|CRS_DEP_TIME|DEP_TIME|WHEELS_ON|TAXI_IN|CRS_ARR_TIME|ARR_TIME|CANCELLED|DISTANCE|
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
|2000-01-01| DL| 1451| BOS| Boston, MA| ATL| Atlanta, GA| 1115| 1113| 1343| 5| 1400| 1348| 0| 946|
|2000-01-01| DL| 1479| BOS| Boston, MA| ATL| Atlanta, GA| 1315| 1311| 1536| 7| 1559| 1543| 0| 946|
|2000-01-01| DL| 1857| BOS| Boston, MA| ATL| Atlanta, GA| 1415| 1414| 1642| 9| 1721| 1651| 0| 946|
|2000-01-01| DL| 1997| BOS| Boston, MA| ATL| Atlanta, GA| 1715| 1720| 1955| 10| 2013| 2005| 0| 946|
|2000-01-01| DL| 2065| BOS| Boston, MA| ATL| Atlanta, GA| 2015| 2010| 2230| 10| 2300| 2240| 0| 946|
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
only showing top 5 rows
PARQUET Schema: struct<**FL_DATE:date**,OP_CARRIER:string,OP_CARRIER_FL_NUM:int,ORIGIN:string,ORIGIN_CITY_NAME:string,DEST:string,DEST_CITY_NAME:string,CRS_DEP_TIME:int,DEP_TIME:int,WHEELS_ON:int,TAXI_IN:int,CRS_ARR_TIME:int,ARR_TIME:int,CANCELLED:int,DISTANCE:int>
Process finished with exit code 0
- inferSchema 옵션을 써서 스키마 자동 추론을 한 경우, flightTimeCsvDF 데이터프레임에서는 FL_DATE:**string** 형으로 인식이 되었다. json 형식 또한 스키마가 자동 추론 되어 date가 string 형식으로 인식되었다.
- 반면, Parquet 파일은 ****데이터와 함께 스키마 정보를 포함하고 있기 때문에 schema 자동 추론의 부정확성을 걱정할 필요가 없다. 터미널 출력 결과를 보면, FL_DATE가 DATE 형식으로 스키마가 정의되어있는 것을 확인할 수 있다.
Creating Spark DataFrame Schema
- How to define Schema
- Programmatically
- using DDL String
Spark에서 데이터를 읽을 때 스키마를 명시하는 방법은 StructType과 SchemaDDL 두 가지로 나뉘며, 이는 데이터 포맷과 사용자의 선호도에 따라 선택된다.
- StructType은 PySpark의 내장 데이터 타입을 사용하여 각 필드를 StructField 형태로 정의하는 방식으로, Python 객체 형태로 직관적이고 유연하게 스키마를 관리할 수 있다. 이는 특히 CSV와 같이 스키마 정보가 포함되지 않은 파일 포맷에서 자주 사용된다.
- 반면, SchemaDDL은 DDL(Data Definition Language) 형식으로, SQL 스키마 정의 문자열을 사용해 스키마를 정의하는 방식이다. 이 방식은 JSON과 같이 반정형 데이터를 다룰 때 SQL과 유사한 형식으로 스키마를 간결하게 표현하는 데 유리하다. Parquet와 같이 자체적으로 스키마 정보를 내포하는 파일 형식은 별도의 스키마 정의 없이도 정확한 데이터 타입을 자동 추론한다. 따라서, CSV는 StructType, JSON은 SchemaDDL, Parquet은 스키마 정의 없이 사용하는 것이 일반적이며, 각 방식은 데이터 포맷과 사용 사례에 따라 유연하게 선택된다.
위에서 스키마 자동추론이 잘못된 스키마를 직접 정의하기 위해 StructType과 SchemaDDL를 사용해 아래처럼 명시적으로 스키마를 정의해주었다.
# 1. How to use DataFrame for CSV, JSON, and Parquet
# 1. Spark Data Types
# 2. How to explicitly define a schema for your data
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from lib.logger import Log4j
if __name__ == "__main__":
spark = SparkSession \\
.builder \\
.master("local[3]") \\
.appName("SparkSchemaDemo") \\
.getOrCreate()
logger = Log4j(spark)
flightSchemaStruct = StructType([
StructField("FL_DATE", DateType()),
StructField("OP_CARRIER", StringType()),
StructField("OP_CARRIER_FL_NUM", IntegerType()),
StructField("ORIGIN", StringType()),
StructField("ORIGIN_CITY_NAME", StringType()),
StructField("DEST", StringType()),
StructField("DEST_CITY_NAME", StringType()),
StructField("CRS_DEP_TIME", IntegerType()),
StructField("DEP_TIME", IntegerType()),
StructField("WHEELS_ON", IntegerType()),
StructField("TAXI_IN", IntegerType()),
StructField("CRS_ARR_TIME", IntegerType()),
StructField("ARR_TIME", IntegerType()),
StructField("CANCELLED", IntegerType()),
StructField("DISTANCE", IntegerType())
])
# column anme and data type separated by a comma.
flightSchemaDDL = """FL_DATE DATE, OP_CARRIER STRING, OP_CARRIER_FL_NUM INT, ORIGIN STRING,
ORIGIN_CITY_NAME STRING, DEST STRING, DEST_CITY_NAME STRING, CRS_DEP_TIME INT, DEP_TIME INT,
WHEELS_ON INT, TAXI_IN INT, CRS_ARR_TIME INT, ARR_TIME INT, CANCELLED INT, DISTANCE INT
"""
# 현재 스키마 정의 안함. inferSchema도 정의 안함.(모두 sting으로 인식됨.)
flightTimeCsvDF = spark.read \\
.format("csv") \\
.option('header', "true") \\
.schema(flightSchemaStruct) \\
.option("mode", "FAILFAST") \\
.option("dateFormat", "M/d/y") \\
.load("data/flight*.csv")
flightTimeCsvDF.show(5)
print("CSV Schema: "+ flightTimeCsvDF.schema.simpleString())
# json & parquet 파일을 읽어올때는 항상 schema를 자동적으로 추론하기 때문에, inferSchema 옵션을 사용할 필요가 X.
flightTimeJsonDF = spark.read \\
.format("json") \\
.schema(flightSchemaDDL)\\
.option("dateFormat", "M/d/y") \\
.load("data/flight*.json")
flightTimeJsonDF.show(5)
print("JSON Schema: " + flightTimeJsonDF.schema.simpleString())
flightTimeParquetDF = spark.read \\
.format("parquet") \\
.load("data/flight*.parquet")
flightTimeParquetDF.show(5)
print("PARQUET Schema: " + flightTimeParquetDF.schema.simpleString())
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
| FL_DATE|OP_CARRIER|OP_CARRIER_FL_NUM|ORIGIN|ORIGIN_CITY_NAME|DEST|DEST_CITY_NAME|CRS_DEP_TIME|DEP_TIME|WHEELS_ON|TAXI_IN|CRS_ARR_TIME|ARR_TIME|CANCELLED|DISTANCE|
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
|2000-01-01| DL| 1451| BOS| Boston, MA| ATL| Atlanta, GA| 1115| 1113| 1343| 5| 1400| 1348| 0| 946|
|2000-01-01| DL| 1479| BOS| Boston, MA| ATL| Atlanta, GA| 1315| 1311| 1536| 7| 1559| 1543| 0| 946|
|2000-01-01| DL| 1857| BOS| Boston, MA| ATL| Atlanta, GA| 1415| 1414| 1642| 9| 1721| 1651| 0| 946|
|2000-01-01| DL| 1997| BOS| Boston, MA| ATL| Atlanta, GA| 1715| 1720| 1955| 10| 2013| 2005| 0| 946|
|2000-01-01| DL| 2065| BOS| Boston, MA| ATL| Atlanta, GA| 2015| 2010| 2230| 10| 2300| 2240| 0| 946|
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
only showing top 5 rows
CSV Schema: struct<FL_DATE:date,OP_CARRIER:string,OP_CARRIER_FL_NUM:int,ORIGIN:string,ORIGIN_CITY_NAME:string,DEST:string,DEST_CITY_NAME:string,CRS_DEP_TIME:int,DEP_TIME:int,WHEELS_ON:int,TAXI_IN:int,CRS_ARR_TIME:int,ARR_TIME:int,CANCELLED:int,DISTANCE:int>
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
| FL_DATE|OP_CARRIER|OP_CARRIER_FL_NUM|ORIGIN|ORIGIN_CITY_NAME|DEST|DEST_CITY_NAME|CRS_DEP_TIME|DEP_TIME|WHEELS_ON|TAXI_IN|CRS_ARR_TIME|ARR_TIME|CANCELLED|DISTANCE|
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
|2000-01-01| DL| 1451| BOS| Boston, MA| ATL| Atlanta, GA| 1115| 1113| 1343| 5| 1400| 1348| 0| 946|
|2000-01-01| DL| 1479| BOS| Boston, MA| ATL| Atlanta, GA| 1315| 1311| 1536| 7| 1559| 1543| 0| 946|
|2000-01-01| DL| 1857| BOS| Boston, MA| ATL| Atlanta, GA| 1415| 1414| 1642| 9| 1721| 1651| 0| 946|
|2000-01-01| DL| 1997| BOS| Boston, MA| ATL| Atlanta, GA| 1715| 1720| 1955| 10| 2013| 2005| 0| 946|
|2000-01-01| DL| 2065| BOS| Boston, MA| ATL| Atlanta, GA| 2015| 2010| 2230| 10| 2300| 2240| 0| 946|
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
only showing top 5 rows
JSON Schema: struct<FL_DATE:date,OP_CARRIER:string,OP_CARRIER_FL_NUM:int,ORIGIN:string,ORIGIN_CITY_NAME:string,DEST:string,DEST_CITY_NAME:string,CRS_DEP_TIME:int,DEP_TIME:int,WHEELS_ON:int,TAXI_IN:int,CRS_ARR_TIME:int,ARR_TIME:int,CANCELLED:int,DISTANCE:int>
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
| FL_DATE|OP_CARRIER|OP_CARRIER_FL_NUM|ORIGIN|ORIGIN_CITY_NAME|DEST|DEST_CITY_NAME|CRS_DEP_TIME|DEP_TIME|WHEELS_ON|TAXI_IN|CRS_ARR_TIME|ARR_TIME|CANCELLED|DISTANCE|
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
|2000-01-01| DL| 1451| BOS| Boston, MA| ATL| Atlanta, GA| 1115| 1113| 1343| 5| 1400| 1348| 0| 946|
|2000-01-01| DL| 1479| BOS| Boston, MA| ATL| Atlanta, GA| 1315| 1311| 1536| 7| 1559| 1543| 0| 946|
|2000-01-01| DL| 1857| BOS| Boston, MA| ATL| Atlanta, GA| 1415| 1414| 1642| 9| 1721| 1651| 0| 946|
|2000-01-01| DL| 1997| BOS| Boston, MA| ATL| Atlanta, GA| 1715| 1720| 1955| 10| 2013| 2005| 0| 946|
|2000-01-01| DL| 2065| BOS| Boston, MA| ATL| Atlanta, GA| 2015| 2010| 2230| 10| 2300| 2240| 0| 946|
+----------+----------+-----------------+------+----------------+----+--------------+------------+--------+---------+-------+------------+--------+---------+--------+
only showing top 5 rows
PARQUET Schema: struct<FL_DATE:date,OP_CARRIER:string,OP_CARRIER_FL_NUM:int,ORIGIN:string,ORIGIN_CITY_NAME:string,DEST:string,DEST_CITY_NAME:string,CRS_DEP_TIME:int,DEP_TIME:int,WHEELS_ON:int,TAXI_IN:int,CRS_ARR_TIME:int,ARR_TIME:int,CANCELLED:int,DISTANCE:int>
Process finished with exit code 0
Writing Your Data and Managing Layout
Apache Spark는 DataFrameWriter API를 통해 다양한 내부 및 외부 데이터 싱크(Data Sink)에 데이터를 쓸 수 있도록 표준화된 인터페이스를 제공한다. DataFrame에서 write 메서드를 호출하면 DataFrameWriter를 사용할 수 있으며, 주요 설정 항목으로는 출력 형식(format), 옵션(options), 저장 모드(save mode), 그리고 **출력 데이터 레이아웃(layout)**을 제어하는 방법이 있다.
첫 번째로, 출력 형식(format)을 지정하는 것이 중요하다. Spark는 기본적으로 CSV, JSON, Parquet, AVRO, ORC와 같은 내부 파일 형식을 지원하며, 별도로 형식을 지정하지 않으면 Parquet이 기본값으로 설정된다. 또한, JDBC, Cassandra, MongoDB, Kafka, Delta Lake와 같은 외부 커뮤니티 및 서드파티 형식도 지원된다.
두 번째는 옵션(options) 설정이다. 데이터 싱크에 따라 다양한 옵션을 지정할 수 있으며, 최소한 대상 경로(target path)는 반드시 설정해야 한다. 파일 기반의 싱크일 경우, 디렉터리 경로를 명확히 지정해야 하며, 경로 내 특정 파일을 대상으로 할 때는 와일드카드를 사용할 수도 있다.
세 번째는 저장 모드(save mode)이다. 이는 지정된 경로에 기존 데이터가 있을 때 Spark가 어떻게 처리할지를 결정한다. append 모드는 기존 데이터를 유지하면서 새로운 데이터를 추가하고, overwrite 모드는 기존 데이터를 삭제하고 새 데이터를 덮어쓴다. errorIfExists 모드는 이미 데이터가 존재하면 오류를 발생시키고, ignore 모드는 대상 경로에 데이터가 없을 때만 데이터를 쓰고, 이미 존재하면 아무 작업도 수행하지 않는다.
마지막으로, 출력 데이터의 레이아웃을 제어하는 방법이 있다. 이는 파일 수와 크기, 파티션과 버킷 구성, 정렬된 데이터 저장 등을 포함한다. 기본적으로 Spark는 DataFrame의 파티션 수만큼 출력 파일을 생성하며, 각 파티션은 개별 Executor 코어에서 병렬로 작성된다. 하지만, 필요에 따라 repartition() 메서드를 사용해 파일 수를 조정할 수도 있다.
데이터를 더 효율적으로 구성하려면 partitionBy()와 bucketBy()를 사용하는 방법이 있다. partitionBy()는 특정 키 열을 기준으로 데이터를 파티셔닝하는 방법으로, 예를 들어 국가 코드나 상태 코드와 같은 단일 열 또는 여러 열을 기준으로 데이터를 나눌 수 있다. 이는 Spark SQL의 성능을 향상시키는 파티션 프루닝(partition pruning) 기법과 함께 사용된다. 반면, bucketBy()는 데이터를 고정된 수의 버킷으로 나누는 방식으로, 이는 Spark 관리 테이블에서만 사용할 수 있다.
또한, sortBy()와 maxRecordsPerFile 옵션도 중요하다. sortBy()는 데이터를 정렬된 형태로 버킷에 저장할 때 사용되며, maxRecordsPerFile은 파일당 최대 레코드 수를 제한하여 비효율적인 대용량 파일 생성을 방지하는 역할을 한다. 이 옵션은 partitionBy()와 함께 사용하거나, 독립적으로 사용할 수도 있다.
결론적으로, Spark의 DataFrameWriter API는 데이터를 다양한 형식으로 저장하는 것뿐만 아니라, 데이터 레이아웃을 세밀하게 제어할 수 있도록 돕는다. 특히, Parquet 형식과 파티셔닝(partitioning)을 적절히 활용하면 성능과 저장 공간 효율성을 극대화할 수 있다. 앞으로 Spark에서 데이터를 내보낼 때는 형식(format), 옵션(options), 저장 모드(save mode), 그리고 레이아웃(layout)을 적절히 설정하는 것이 중요하다.

아래는 DataFramWriter API와 PartitionBy 메서드를 이용해 데이터를 불러오는 실습 코드이다.
from pyspark.sql import SparkSession
from pyspark.sql.functions import spark_partition_id
from pyspark.sql.types import *
if __name__ == "__main__":
# Create Spark session
spark = SparkSession \\
.builder \\
.master("local[3]") \\
.appName("SparkSchemaDemo") \\
.config("spark.jars.packages", "org.apache.spark:spark-avro_2.12:3.4.4") \\
.getOrCreate()
# Read the data sources
flightTimeParquetDF = spark.read \\
.format("parquet") \\
.load("dataSource/flight*.parquet")
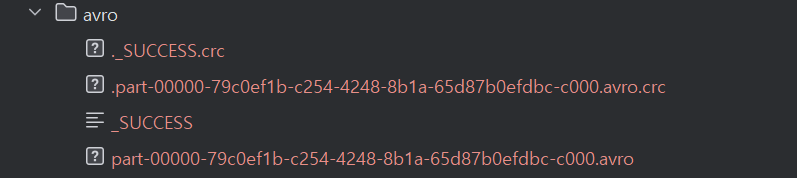
# Write the DataFrames as an Avro output.
flightTimeParquetDF.write \\
.format("avro") \\
.mode("overwrite") \\
.option("path", "avro/") \\
.save()
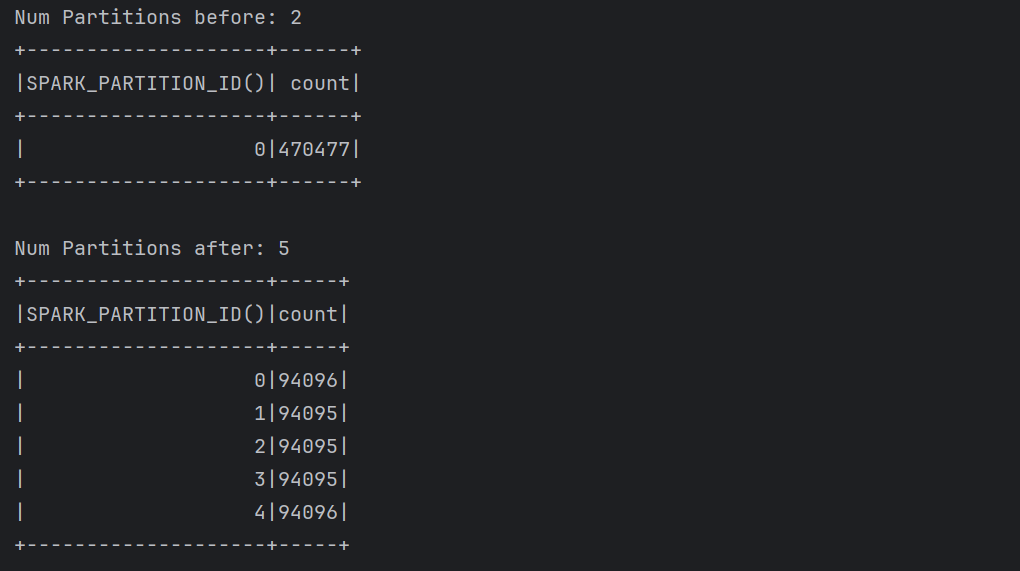
print("Num Partitions before: " + str(flightTimeParquetDF.rdd.getNumPartitions()))
flightTimeParquetDF.groupBy(spark_partition_id()).count().show()
# Make 5 partitions
partitionedDF = flightTimeParquetDF.repartition(5)
print("Num Partitions after: " + str(partitionedDF.rdd.getNumPartitions()))
partitionedDF.groupBy((spark_partition_id())).count().show()
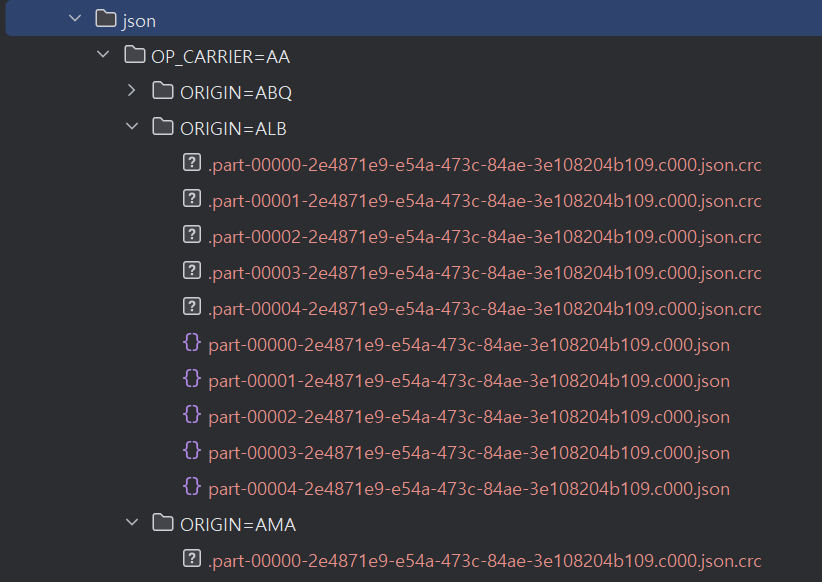
partitionedDF.write \\
.format("json") \\
.mode("overwrite") \\
.option("path", "json/") \\
.partitionBy("OP_CARRIER", "ORIGIN") \\
.option("maxRecordsPerFile", 10000) \\
.save()
코드를 실행하였을 때, 아래와 같이 partition 개수와 partition대로 데이터 파일이 저장된 것을 확인할 수 있다.
Spark Databases and Tables
Spark에서의 테이블은 Managed Table과 Unmanaged Table로 나뉘어진다. 데이터 프로세싱의 용도와 목적에 맞게 적절한 방식을 사용하여 운영해야한다.
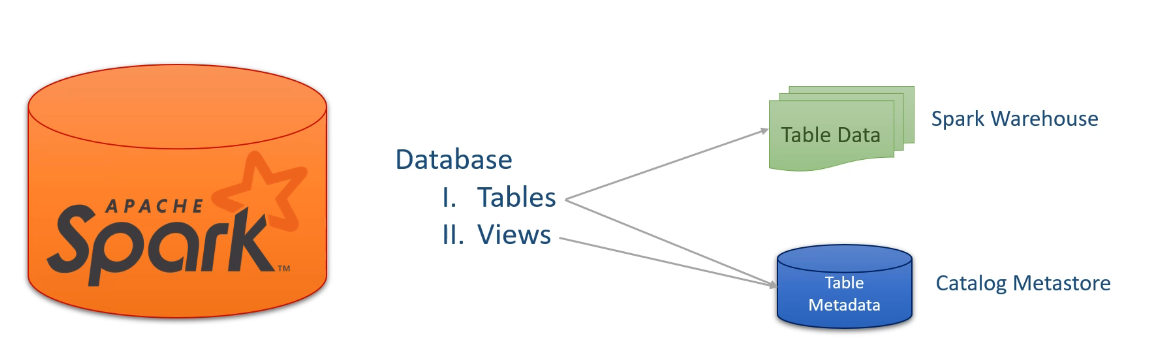
관리형 테이블(Managed Tables)
- Spark는 해당 테이블의 데이터와 메타데이터를 모두 관리한다.
- 테이블이 생성되면 Spark는 메타스토어에 테이블 정보를 저장하고, 데이터를 Spark의 기본 저장 디렉토리(즉, spark.sql.warehouse.dir) 내부에 저장한다.
- spark.sql.warehouse.dir은 모든 관리형 테이블이 저장되는 기본 디렉토리이며, 클러스터 관리자가 이를 설정한다. 이 경로는 런타임에 변경할 수 없고, 변경해서도 안 된다.
비관리형 테이블(외부 테이블, Unmanaged Tables / External Tables)
- 비관리형 테이블은 데이터를 사용자가 원하는 경로에 저장할 수 있도록 유연성을 제공한다.
- 이미 특정 디렉토리에 저장된 데이터를 Spark SQL을 통해 분석하고 싶다면, 이를 비관리형 테이블로 등록할 수 있다.
- 그러나 Spark SQL 엔진은 해당 데이터 파일 자체를 직접 관리하지 않는다.
- Spark가 이 데이터를 활용하려면, 사용자가 직접 비관리형 테이블을 생성하고 기존 데이터 파일을 Spark 테이블에 매핑해야 한다.
- 비관리형 테이블을 삭제하면 Spark는 메타데이터만 제거하며, 데이터 파일 자체는 삭제되지 않는다.
Working with Spark SQL Tables
from pyspark.sql import *
# Create a managed table and save DataFame to the Spark Table
if __name__ == "__main__":
spark = SparkSession \\
.builder \\
.master("local[3]") \\
.appName("SparkSQLTableDemo") \\
.config("spark.jars.packages", "org.apache.spark:spark-avro_2.12:3.4.4") \\
.config("spark.jars.packages", "org.apache.spark:spark-hive_2.12:3.4.4") \\
.enableHiveSupport() \\
.getOrCreate()
flightTimeParquetDF = spark.read \\
.format("parquet") \\
.load("dataSource/")
spark.sql("CREATE DATABASE IF NOT EXISTS AIRLINE_DB")
spark.catalog.setCurrentDatabase("AIRLINE_DB")
# bucketBy: allows user to restrict the number of partitions
flightTimeParquetDF.write \\
.format("csv") \\
.mode("overwrite") \\
.bucketBy(5, "OP_CARRIER", "ORIGIN") \\
.sortBy("OP_CARRIER", "ORIGIN") \\
.saveAsTable("flight_data_tbl")
print(spark.catalog.listTables("AIRLINE_DB"))
위 코드에서는,
데이터프레임을 csv 형식으로 저장할 때, bucketBy(5, "OP_CARRIER", "ORIGIN")을 사용하여 데이터를 5개의 버킷으로 나눈다. 이 과정에서 OP_CARRIER와 ORIGIN을 기준으로 해싱하여 동일한 키 조합을 가진 데이터가 같은 버킷에 저장되도록 한다. 이후 sortBy("OP_CARRIER", "ORIGIN")을 적용하여 데이터를 OP_CARRIER와 ORIGIN 기준으로 정렬한 후, saveAsTable("flight_data_tbl")을 사용하여 AIRLINE_DB에 flight_data_tbl이라는 테이블로 저장한다.
이 테이블은 Spark의 관리형 테이블이므로, Spark가 데이터 파일뿐만 아니라 해당 테이블의 메타데이터도 관리한다. 따라서 다른 SQL 기반의 툴이나 JDBC/ODBC 연결을 통해 테이블을 직접 조회할 수 있다.
마지막으로, spark.catalog.listTables("AIRLINE_DB")를 호출하여 현재 AIRLINE_DB 데이터베이스에 존재하는 테이블 목록을 출력한다. 이 과정을 통해, 사용자는 Spark SQL을 이용하여 데이터를 로드하고, Hive Metastore를 활용하여 관리형 테이블을 생성하고, 버킷팅과 정렬을 적용하여 데이터를 저장하는 과정을 수행할 수 있다.
이때 buckeyBy를 5로 설정했기 때문에, 5개의 버킷 안에 파일이 들어가도록 강제된다.
- buckeyBy란??
- bucketBy는 지정된 개수(여기서는 5)의 버킷으로 데이터를 나누는 과정에서, 주어진 컬럼들의 조합을 해싱하여 특정 버킷에 할당한다. 즉, "OP_CARRIER"와 "ORIGIN" 컬럼의 값을 조합하여 해시 값을 생성하고, 그 값을 5로 나눈 나머지를 사용하여 해당 데이터를 어느 버킷에 넣을지 결정한다.