Apache Spark는 대규모 데이터 처리와 분석을 효율적으로 수행할 수 있도록 설계된 분산 처리 플랫폼입니다. 특히, Hadoop의 MapReduce 모델을 개선하고 단순화하는 것을 목표로 개발되었다.
Spark의 핵심 개념인 RDD, DataFrame, Dataset과 Spark SQL의 최적화 엔진인 Catalyst Optimizer에 대해 알아보고자 한다.

1. Spark의 RDD(Resilient Distributed Dataset)
Spark의 RDD는 대규모 데이터 처리의 기본 단위로, 데이터를 분산된 클러스터에서 효율적으로 처리할 수 있도록 설계된 핵심 데이터 구조이다.
RDD는 단순한 데이터 구조를 가지기 때문에 Schema와 row/column 구조가 없다. RDD는 기본적으로 데이터 레코드를 담는 자료구조이다.
python에서의 dict, tuple, list와 같은 언어 네이티브 객체로 데이터를 다룬다.
RDD는 Spark의 가장 기본적인 데이터 추상화 계층이다. Immutability, Distributed, Fault-Tolerance를 특징으로 한다. Spark의 모든 데이터 처리는 RDD 형태로 표현되고, 분산된 클러스터 환경에서 데이터를 효율적으로 처리할 수 있도록 설계되었다.
* Immutability: 한 번 생성된 RDD는 변경할 수 없으며, Transformation(변환) 과정을 통해 새로운 RDD를 생성한다.
* Fault-Tolearance: Spark는 RDD 생성 방법에 대한 Lineage를 저장하고 있어, 특정 노드의 장애가 발생하더라도 다른 노드에서 동일한 데이터를 재생성할 수 있다.
* Fault-Tolerance: Transformation 연산은 실제로 실행되지 않고, Action이 호출될 때 비로소 실행된다.
하지만 RDD는 저수준 API이기 때문에 Spark에서 사용을 권장하지 않는다.
데이터 그룹화 및 집계 시에 많은 코드를 직접 작성해야 한다. ex) map, reduceByKey, mapValues 등의 여러 단계 작업이 필요하다.
또한 RDD는 Spark의 최적화 엔진인 Catalyst의 혜택을 받지 못한다. Spark는 RDD 내부의 데이터 구조를 알 수 없고, 사용자의 람다 함수 내부도 분석을할 수 없다. 조금 원시적이고 구식의 버전.. 이라고 한다.
📝 RDD를 활용한 데이터 처리 예제
아래는 RDD를 활용해서 데이터를 처리하는 간단한 예제이다.
데이터 변환하고 불필요한 문자(double quotes 같은.)를 제거한 뒤, 각 행을 namedtuple 형식으로 매핑한다.
40세 미만의 사용자만 추출하고, 국가별로 사용자수를 집계(reduceByKey)해 최종 결과를 수집(collect)하고 출력하는 순서이다.
간단한 동작을 수행하는데, 코드가 복잡하다는 단점이 있다.
# create a SparkConf object
# create a Spark Session using SparkConf
# use the spark session to read the data file
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# from lib.logger import Log4j
import sys
from collections import namedtuple
SurveyRecord = namedtuple("SurveyRecord", ["Age", "Gender", "Country", "State"])
if __name__ == "__main__":
conf = SparkConf() \
.setMaster("local[3]") \
.setAppName("HelloRDD")
# sc = SparkContext(conf=conf)
spark = SparkSession \
.builder \
.config(conf = conf) \
.getOrCreate()
# sc = spark.sparkContext(conf=conf)
#logger = Log4j(spark)
sc = spark.sparkContext
if len(sys.argv) != 2:
#logger.error("Usage: HelloSpark <filename>")
sys.exit(-1)
linesRDD = sc.textFile(sys.argv[1])
# Transformation & Action
# RDD havs no schema or a row/column structure
# just lines of file
partitionedRDD = linesRDD.repartition(2)
# double quotes 제거 + comma 기준으로 word split
colsRDD = partitionedRDD.map(lambda line: line.replace('"', '').split(","))
# namedtuple 생성하여 스키마와 데이터 타입 부여
selectRDD = colsRDD.map(lambda cols: SurveyRecord(int(cols[1]), cols[2], cols[3], cols[4]))
filteredRDD = selectRDD.filter(lambda r: r.Age < 40)
kvRDD = filteredRDD.map(lambda r: (r.Country, 1)) # key: Country, value: 1
countRDD = kvRDD.reduceByKey(lambda v1, v2: v1+v2)
colsList = countRDD.collect()
for x in colsList:
print(x)
2. Spark의 DataFrame과 Dataset (RDD 한계 극복)
RDD 복잡성을 개선하기 위해서 Spark에서는 Dataframe API와 Dataset API를 도입했다.
DataFrame은 행과 열로 구성된 테이블 형태의 구조로, SQL과 유사하게 데이터를 다룰 수 있다. SparkSQL 엔진을 활용해서 최적화된 실행 계획을 수립하고, Catalyst Optimizer의 다양한 최적화 기법을 적용받을 수가 있다.
Dataset은 RDD의 강한 타입 안정성과 Dataframe의 최적화된 실행 성능을 결합한 형태이다. Java와 Scala에서 주로 사용되고, Python엣는 DataFrame만 사용할 수 있어서 실습을 해보지는 못했다.
위에서 작성했던 RDD 코드를 아래의 SQL문을 활용해 간소화할 수 있다.
import sys
from pyspark.sql import SparkSession
# from lib.logger import Log4j
if __name__ == "__main__":
spark = SparkSession \
.builder \
.master("local[3]") \
.appName("HelloSparkSQL") \
.getOrCreate()
# logger = Log4j(spark)
if len(sys.argv) !=2:
# logger.error("Usage: HelloSpark <filename>")
sys.exit(-1)
surveyDF = spark.read \
.option("header", "true") \
.option("inferSchema", "true") \
.option("quote", '"') \
.csv(sys.argv[1])
surveyDF.createOrReplaceTempView("survey_tbl")
countDF = spark.sql("select Country, count(1) as count from survey_tbl where Age<40 group by Country")
countDF.show()3. Spark SQL과 Catalyst Optimizer
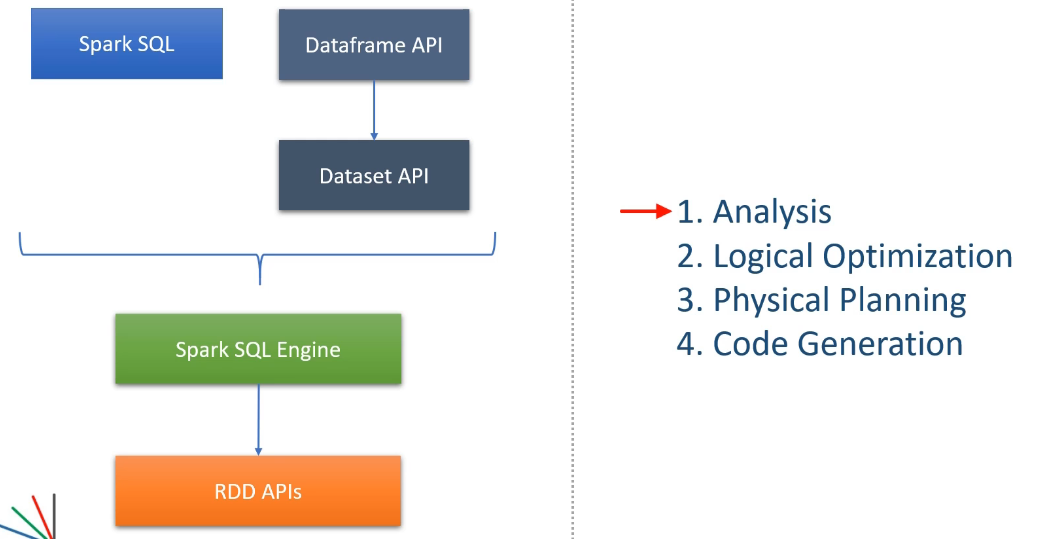
Spark SQL이 DataFrame과 Dataset을 기반으로 SQL과 유사한 쿼리를 실행하는 엔진이다. 해당 엔진은 Catalyst Optimizer로 최적화를 수행한다.
1. Analysis
Spark SQL은 사용자의 쿼리를 AST(Abstract Syntax Tree) 형태로 분석하고, 테이블과 열의 메타데이터를 참조해 논리적 계획(Logical Plan)을 생성한다.
2. Logical Optimization
논리적 계획에 Rule-based Optimization과 Cost-based Optimization을 적용해 여러 실행 계회글 수립한다. 대표적인 최적화 기법은 아래와 같다.
ex) predicate pushdown(불필요한 데이터 초기에 필터링해서 I/O 비용 감소), projection pruning(필요한 열만 선택해 처리하는 최적화), boolean expression simplification(논리식을 간소화해 불필요한 연산을 줄임), and constant folding(상수 연산 미리 계산해놔서 실행시 불필요한 연산을 줄임).
3. Physical Planning
최적화된 논리적 계획중 가장 비용이 낮은 계획을 선택하고, RDD 연산 형태의 물리적 계획으로 변환한다. 이 과정에서 Spark 클러스터 상에서 어떤 방식으로 작업을 수행할 지 결정한다.
4. Code Generation
마지막으로, Whole-Stage Code Generation이라는 기법을 통해서 효율적인 Java 바이트코드를 생성한다.
CPU와 메모리를 최대한 활용하도록 설계된다고 한다.(Spark2.0에서 도입된 Project Tungsten의 일환)