Spark Development Environments는 클라우드 플랫폼과 온프레미스 플랫폼에서 실행 가능하다.
Cloud Platforms → Notebook, Databricks Cloud
On-premise Platforms → Python IDE, Clouderaa Platform
Databricks에서 실행하는 방법과, 로컬 컴퓨터에 설치해서 실행하는 방법을 살펴보자.
Databricks에서 실행하는 법
- 아래 링크에서 계정 생성후 ,
https://www.databricks.com/try-databricks#account
“Get Started with community ed

User > Create >Folder (MyFirstProject로 폴더 생성)
Create > Notebook 클릭해서 생성한 폴더 안에 Notebook 생성. 여기서 Notebook은 Databricks에서의 code file이라고 생각하면 된다.
Spark는 cluster machine이 있어야 코드를 실행할 수 있다.
distributed cluster 위에서 실행되기 때문이다.
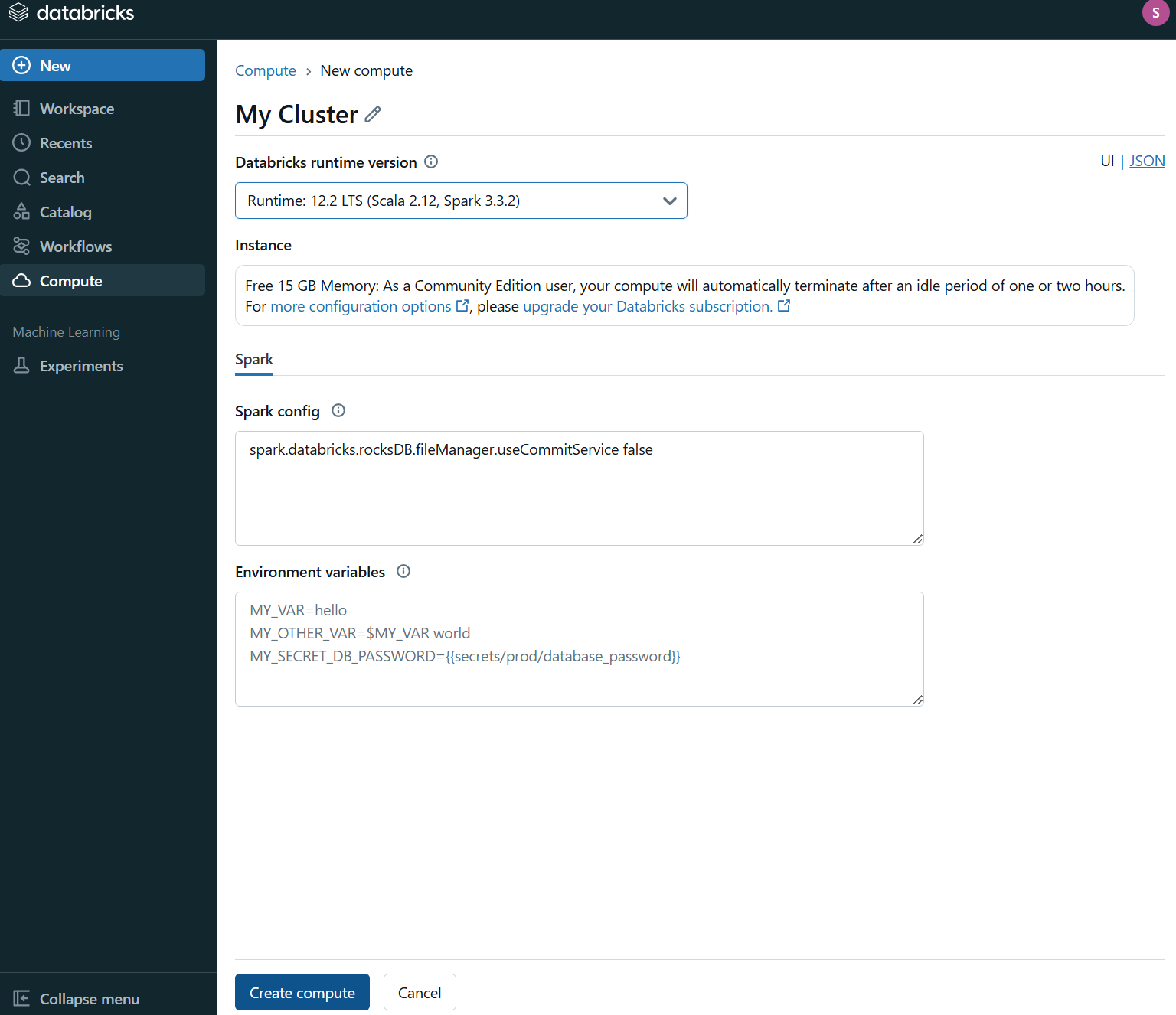
아래처럼 생성한 Cluster를 Notebook에 attach해줘야 함.

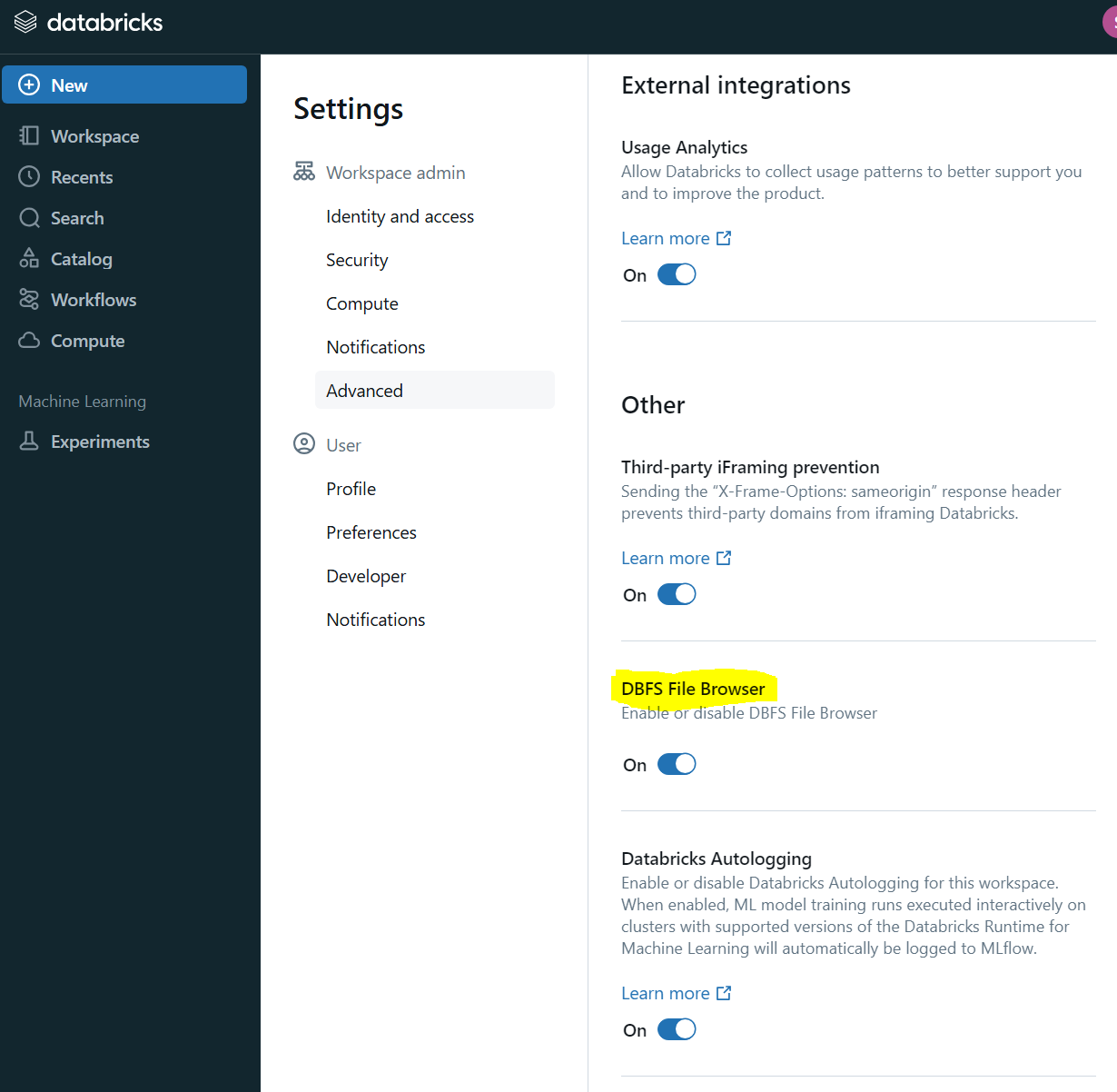
이제는 Databricks에서 제공하는 Cloud Storage 서비스에 접근해보려고 한다. 그 전에, 우측 상단사용자 프로필 클릭해서 Settings에 들어간 다음, Workspace admin 탭에서 Advanced 메뉴를 클릭해 DBFS File Browser 옵션을 활성화 해준다.
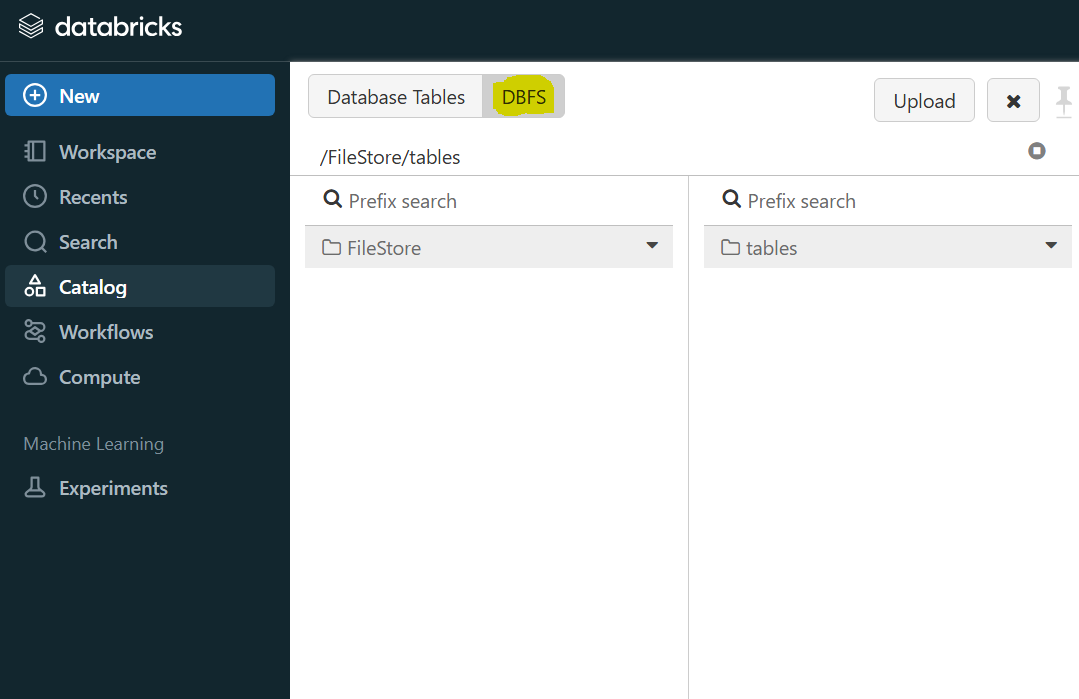
그 후, 좌측 상단 DBFS를 클릭한 후, tables에 샘플로 업로드할 csv 파일을 첨부한다.

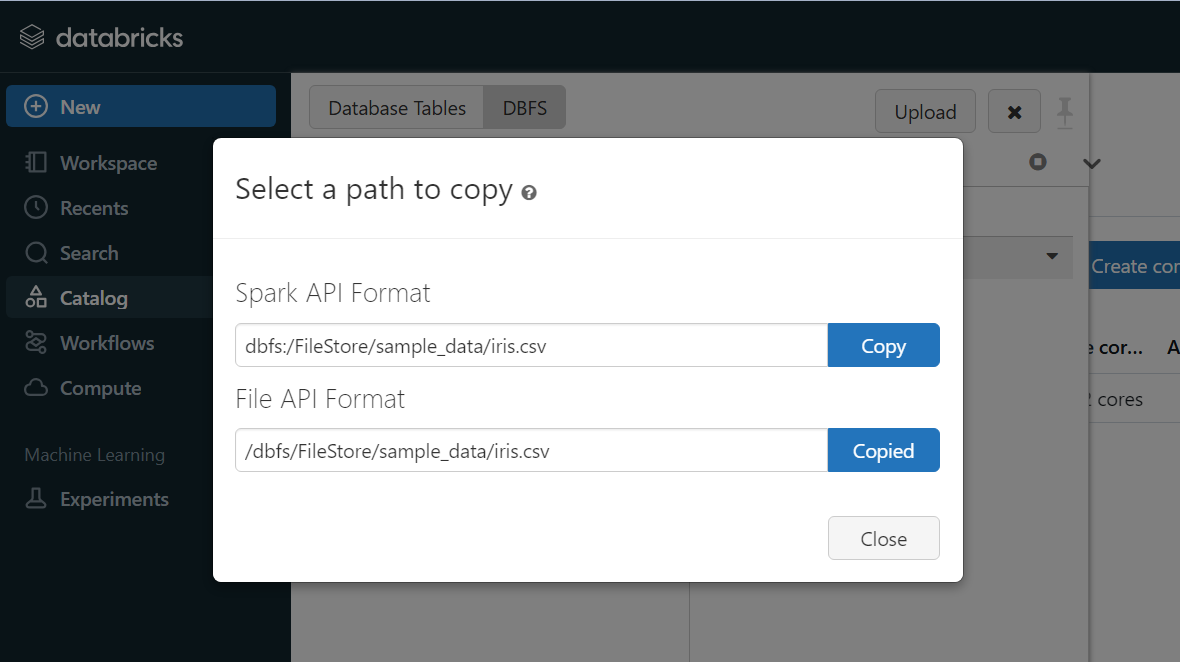
업로드한 File Path를 복사한 후, Workspace에서 작성했던 코드에 파일경로를 붙여넣고 코드를 실행한다.
테스트용으로 데이터셋을 로드한 후, 붓꽃 색 그룹별 평균 가격을 구해 차트로 도식화해보았다.

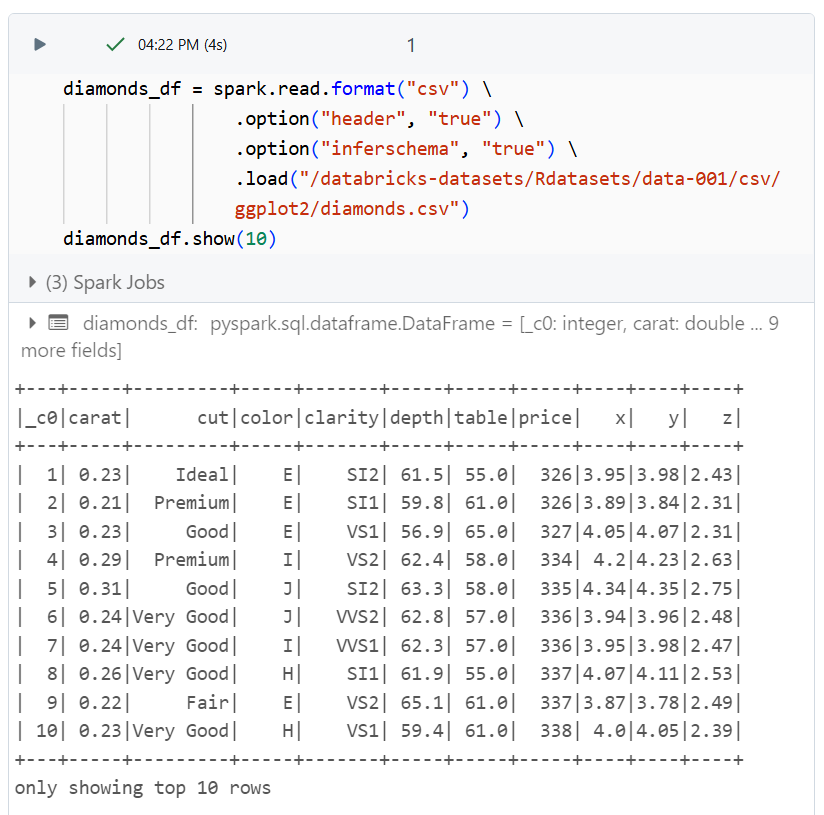
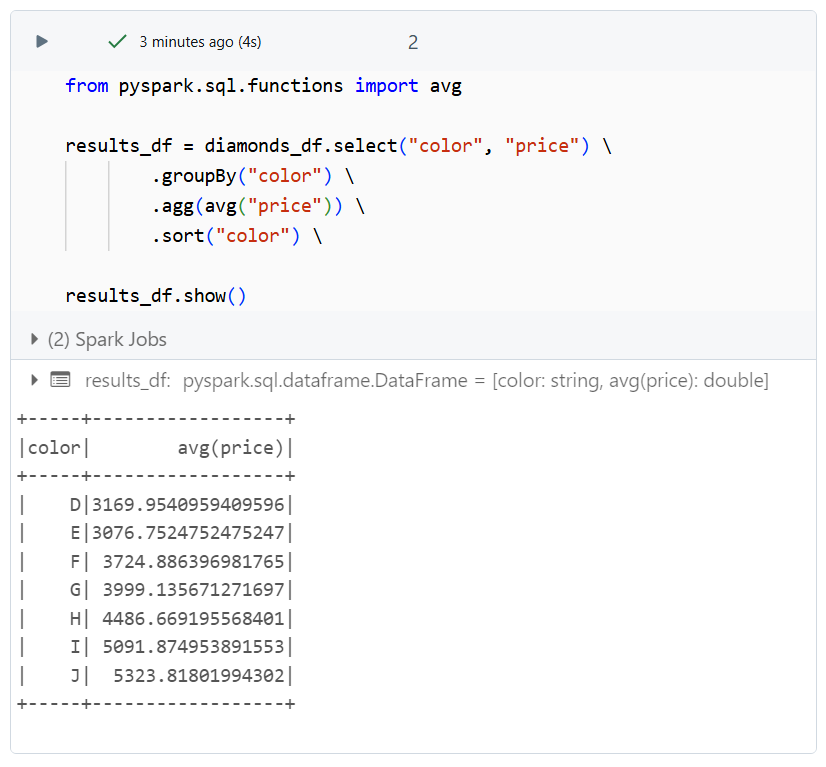
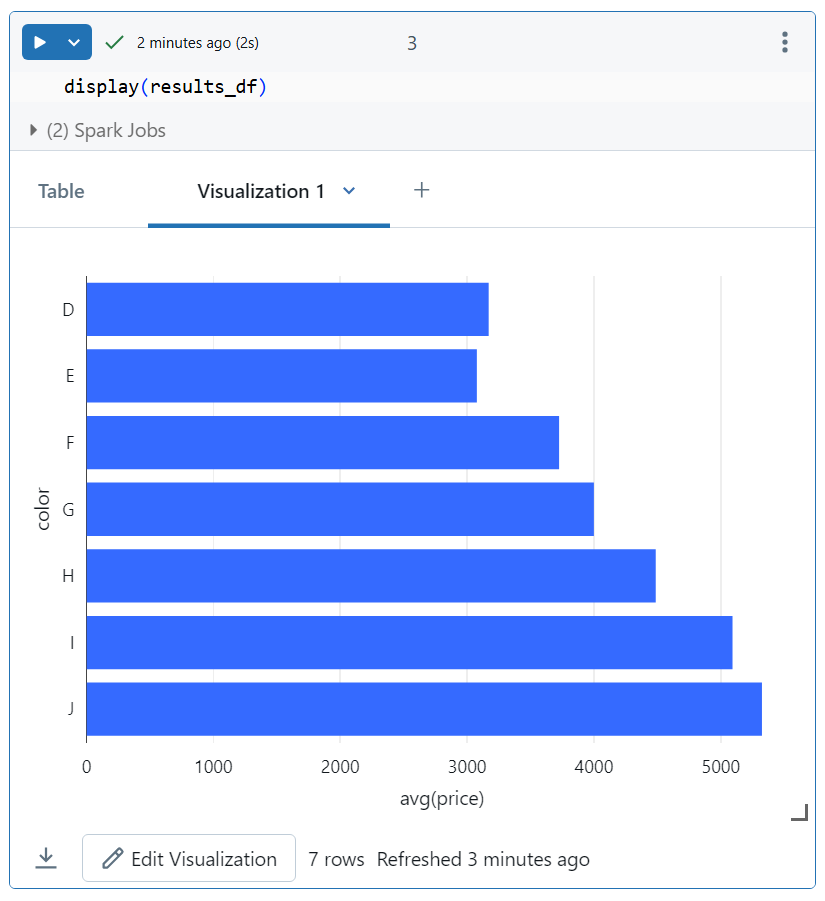
로컬 컴퓨터에서 실행하는 법
우선, 1) JDK 설치 2) Python 설치 3) Spark 설치가 필요한데, 환경변수 설정도 해주어야 하므로 로컬에서 설치 및 실행하는 방법에 대해 차례대로 알아보자.
우선, Spark와의 호환성을 위해 JDK 8 혹은 JDK 11 버전을 사용해야 한다.
https://jdk.java.net/java-se-ri/11-MR3
운영체제에 맞는 폴더 다운로드 후 압축해제한다.
setx JAVA_HOME "C:\Program Files\Java\jdk-11"
setx PATH "%PATH%;JAVA_HOMW%\bin"
java -version
Python도 없는 경우 위와같이 설치해주고 환경변수 설정 해준다.
그 다음 아래 레포지토리 가서 zip 파일 다운받고, HADOOP_HOME이랑 PATH 환경변수 설정해준다.
https://github.com/cdarlint/winutils
GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows - cdarlint/winutils
github.com
나는 hadoop-3.2.2를 아래 경로에 넣어준 후, 환경변수를 설정했다.

아래에서 다운받을 Hadoop version 선택해주고,
https://www.apache.org/dyn/closer.lua/spark/spark-3.4.4/spark-3.4.4-bin-hadoop3.tgz
*.tgz 파일 다운 받았으면 ,압축 풀어서 그 폴더 E:\demo 폴더 하위에 복붙해준다. 그리고 위와 동일한 방식으로 SPARK_HOME, PATH 설정해준다.
spark가 cmd에서 실행되는 것을 확인하고 나면, pycharm에서 spark를 열어서 사용할 것이다.
pyspark 실행이 완료된것을 확인 할 수 있다.
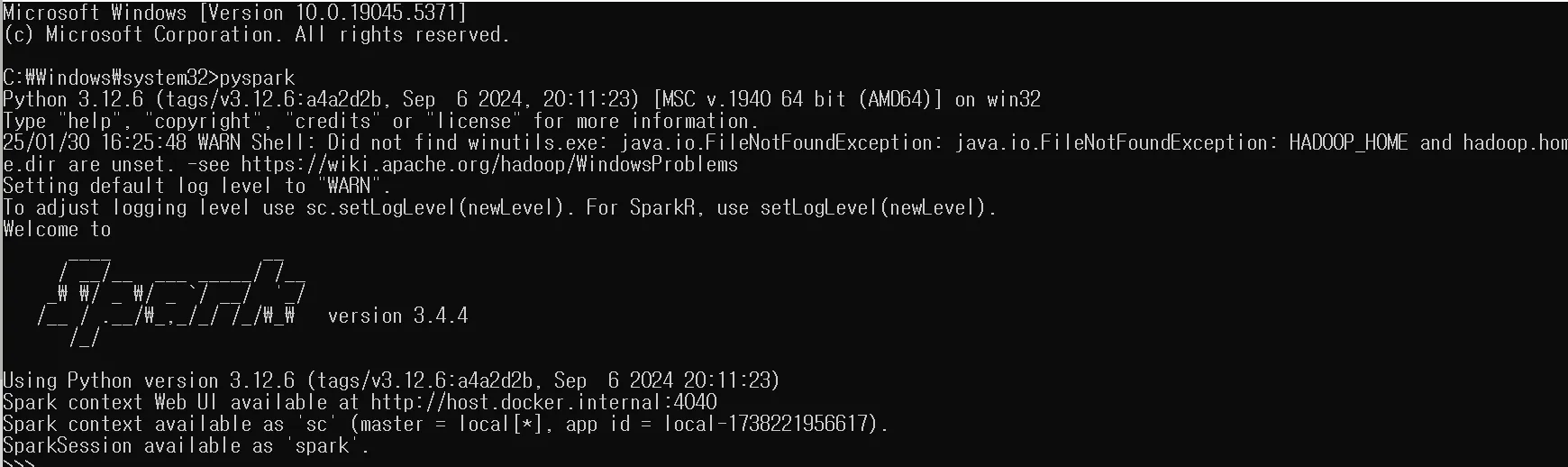
+) 실행 오류가 나는경우 PYTHONPATH 환경설정도 해주자.

E:\demo\HelloSpark 해당 경로에 Pycharm에서 새 프로젝트를 생성했다.
이를 Pycharm IDE에
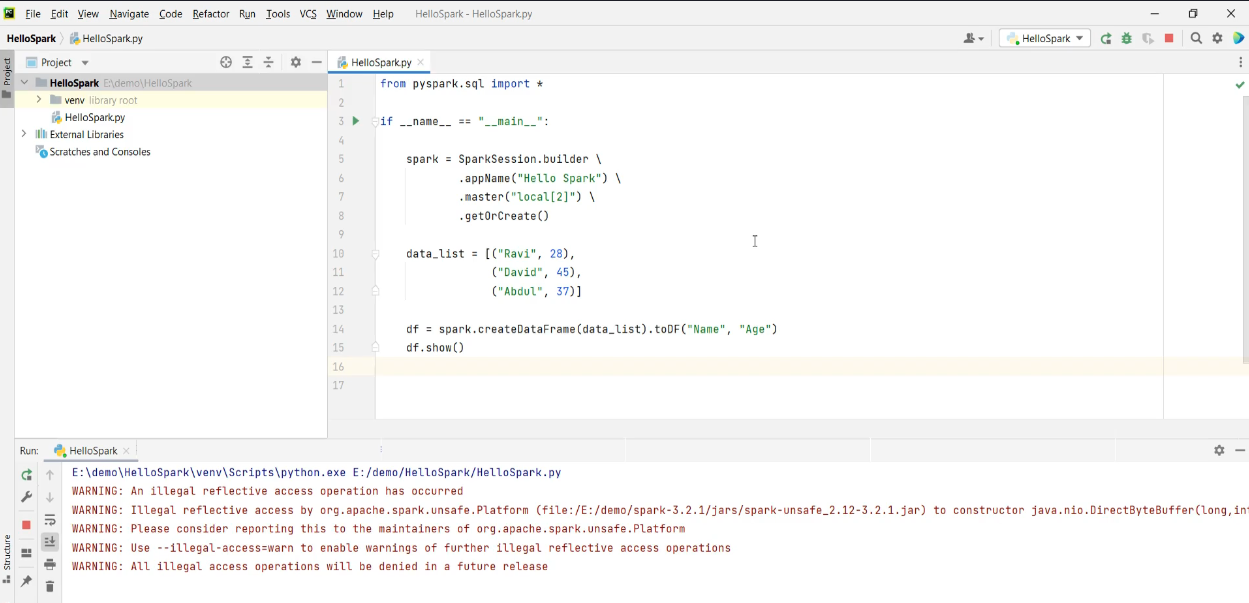
서 열 수 있다.